Neat-Freak: The Skill That Keeps Your AI Agent's Brain From Rotting
Your AI agent just helped you refactor five API routes, add three new environment variables, and migrate from SQLite to PostgreSQL. The code is beautiful. Tests pass. You feel great.
Next week, you open a new session. Your agent confidently suggests using the deprecated_legacy_endpoint because that's what CLAUDE.md still lists. It tries to connect to SQLite — which you removed seven days ago. It forgets that REDIS_URL was renamed to CACHE_URL.
This is not a model hallucination. This is documentation brain rot. And it's one of the most under-discussed problems in AI-assisted development.
The Silent Killer of AI Agent Productivity
In the traditional developer workflow, documentation lag was annoying but survivable. A human would skim outdated docs, roll their eyes, and grep the codebase. But AI agents read documentation literally and trust it completely. When the gap between code and documentation widens, agents become progressively dumber — not because the model degraded, but because the knowledge substrate it drinks from has spoiled.
This problem is structural. Here's why:
- Code changes fast, often multiple times per session
- CLAUDE.md / AGENTS.md are meant to be updated manually but rarely are
- docs/ directories are for humans, and humans forget to update them
- Agent memory accumulates cruft: relative timestamps ("yesterday"), completed TODOs that were never cleaned up, and contradictory facts from different sessions
Each of these is a separate layer with a distinct audience. If you only fix one, the others keep rotting. And fixing them by hand after every coding session is tedious enough that almost nobody does it.
Enter neat-freak
neat-freak (洁癖, "obsessive cleanliness") is an open-source agent skill created by KKKKhazix (数字生命卡兹克), a prominent Chinese AI content creator with 7,700+ GitHub stars on his skills repository. It's designed to run at the end of a development session — triggered by /neat, /sync, or natural language like "整理一下" (tidy up) — and it systematically reconciles everything the session touched against three layers of project knowledge.
What makes neat-freak different from a simple "update your CLAUDE.md" reminder is that it approaches the problem like an editor, not a notetaker. It doesn't append. It audits, merges, corrects, and deletes.
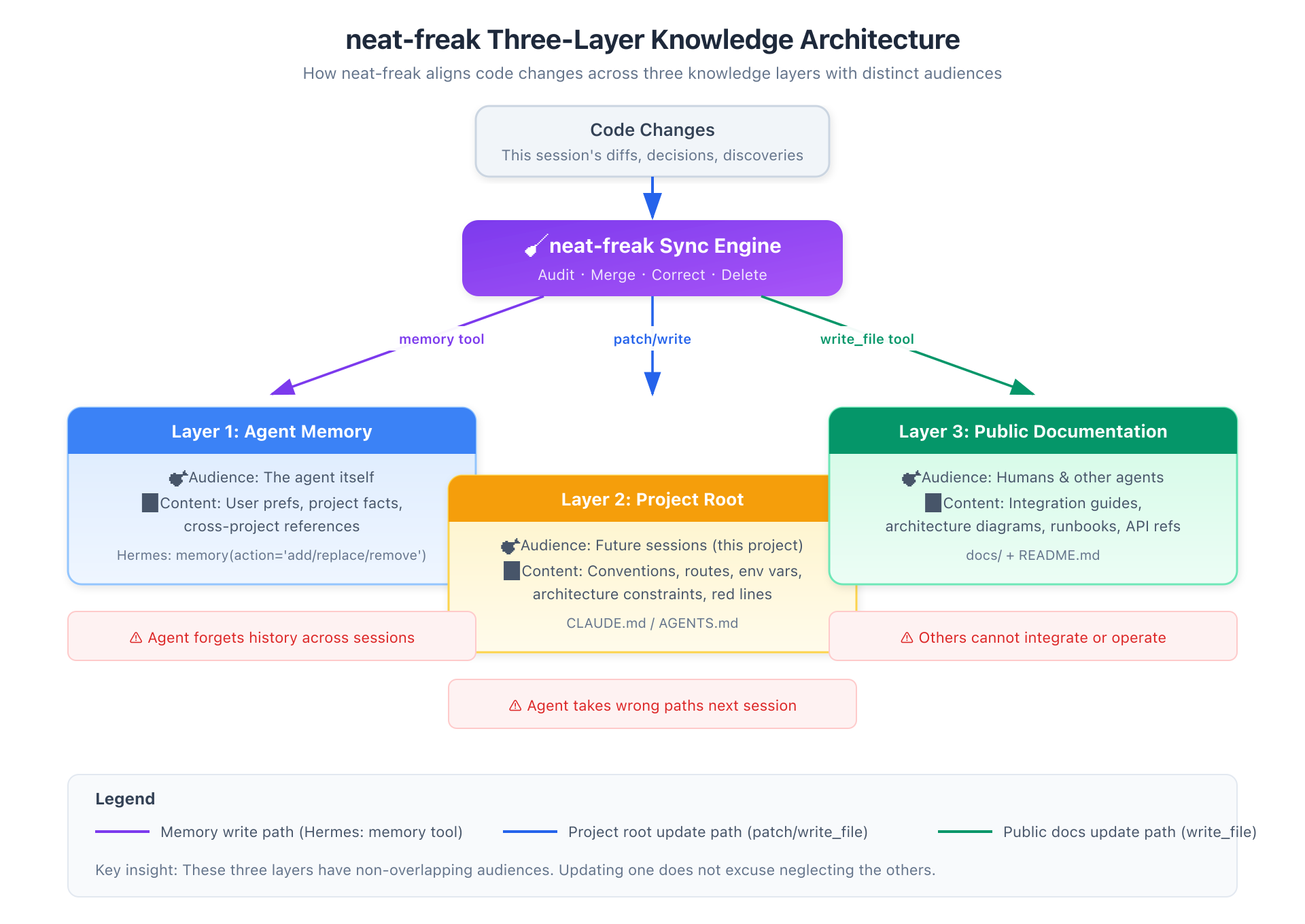
The Three-Layer Knowledge Model
neat-freak's architecture rests on a clear separation of concerns:
| Layer | Location | Audience | Responsibility |
|---|---|---|---|
| Agent Memory | Platform-specific (Claude: ~/.claude/projects/.../memory/, Hermes: memory tool) |
The agent itself, across sessions | Personal preferences, non-obvious project facts, cross-project references |
| Project Root | CLAUDE.md / AGENTS.md |
The agent in future sessions on this project | Project conventions, architecture constraints, environment variable tables, route inventories |
| Public Docs | docs/ + README.md |
Human colleagues, downstream developers, future agents from other platforms | Integration guides, architecture diagrams, runbooks, API references |
The critical insight: these three layers have non-overlapping audiences. Writing "added five new device flow routes" in CLAUDE.md is not the same as writing "how downstream services should call these routes" in docs/integration-guide.md. The former reminds tomorrow's agent. The latter teaches tomorrow's human colleague. Both must happen.
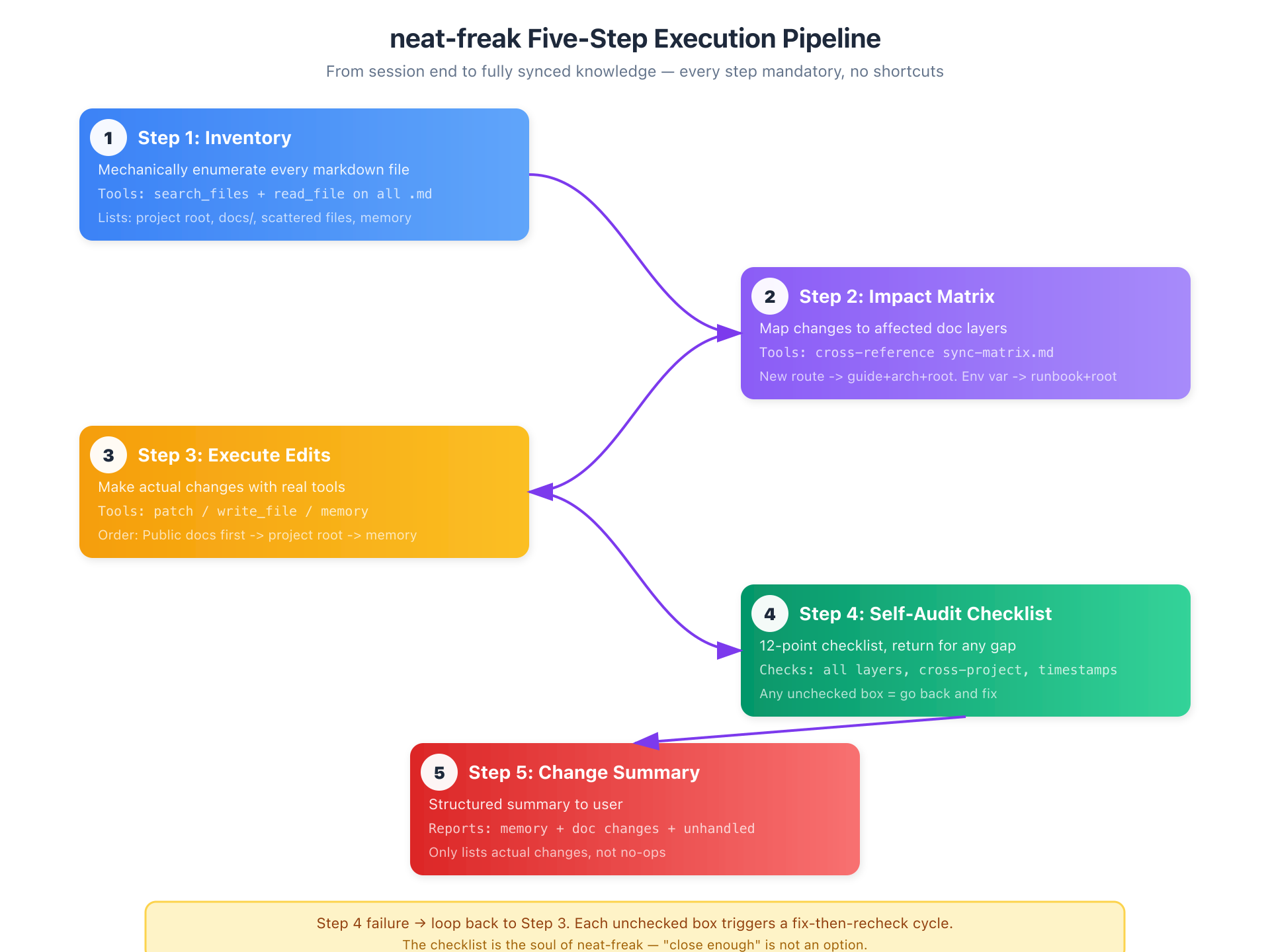
The Five-Step Execution Pipeline
When triggered, neat-freak follows a rigorous five-step process:
Step 1: Inventory. It mechanically enumerates every markdown file in the project — root, docs/, scattered .md files, agent memory files — and reads them all. No assumptions. No shortcuts. Missing files are noted, not ignored.
Step 2: Impact Matrix. This is neat-freak's intellectual core. Instead of asking "what new facts did the conversation produce?", it asks "what documentation layers do these facts affect?" It maintains a mapping table:
- New API route → CLAUDE.md route list + integration guide + architecture doc
- Environment variable change → CLAUDE.md env table + runbook + downstream integration docs
- Database schema change → CLAUDE.md + architecture's Data Model section
- Cross-project API change → upstream docs + downstream docs (the #1 failure mode)
- Memory cleanup → replace relative timestamps with absolute dates, merge duplicates, delete completed TODOs
Step 3: Execute Edits. neat-freak doesn't describe what should change — it makes the changes. Using the platform's native editing tools, it modifies files, creates new ones, and deletes obsolete content. The order is intentional: public docs first (highest impact on others), then project root markdown, then agent memory.
Step 4: Self-Audit Checklist. A 12-point checklist prevents the most common failure: "I updated CLAUDE.md, must be done." Did every integration guide get updated? Are all relative timestamps gone? Did downstream project docs get touched for cross-project changes? If any box can't be checked, neat-freak goes back and fills the gap.
Step 5: Change Summary. A structured summary to the user: what changed in memory, what changed in documentation (per project), and what was left unhandled (only for cases requiring human judgment).
Horizontal Comparison: Why Not Just AutoDream?
Claude Code ships with a built-in feature called AutoDream that updates agent memory after sessions. It's a step in the right direction, but it operates on only one layer: the agent's internal memory. It doesn't touch CLAUDE.md. It doesn't touch docs/. It doesn't handle cross-project impact.
If you exclusively use Claude Code and your projects are single-developer silos, AutoDream might suffice. But the moment a colleague needs to understand your system, or a downstream service needs updated integration docs, the gap becomes visible and costly.
neat-freak is also intentionally cross-platform. The same SKILL.md works on Claude Code, OpenAI Codex, OpenCode, and OpenClaw. (We also adapted it for Hermes Agent — more on that below.)
Multi-Angle Assessment
I evaluated neat-freak across five dimensions before adopting it:
| Dimension | Score | Rationale |
|---|---|---|
| Fills a real gap | ★★★★★ | Nobody systematically syncs all three knowledge layers post-session. This is genuinely unsolved. |
| Source trustworthiness | ★★★★☆ | 7,733 stars, 1,158 forks, well-known author with public explanatory article. Install count is modest (300) but the GitHub signal more than compensates. |
| Cross-platform portability | ★★★★☆ | Designed as a standard Agent Skill. The conceptual model transfers cleanly across platforms; only the tool bindings need mapping. |
| Workflow integration | ★★★★☆ | The five-step process is systematic enough to be reliable without being so rigid that it breaks on unconventional project structures. |
| Risk of over-triggering | ★★★☆☆ | The natural-language triggers ("整理一下", "tidy up") can fire unintentionally, but the skill's inventory phase is read-only — so false triggers are harmless. |
The biggest adoption risk is discipline: neat-freak is only useful if you actually run it. But compared to the alternative — manually auditing three layers of documentation after every non-trivial session — it's a massive time-saver and quality guarantee.
Hermes Agent Adaptation
Since I use Hermes Agent as my primary AI coding environment, I needed to adapt neat-freak's tool bindings. The original skill assumes Claude Code's file-based memory system (~/.claude/projects/.../memory/MEMORY.md) and its native editing tools.
Here's the mapping for Hermes:
| Original Concept | Hermes Equivalent |
|---|---|
| Claude memory files | memory tool (add/replace/remove) |
| User preferences | memory(target='user') |
| File editing | patch / write_file tools |
| Cross-session recall | session_search |
| Skill management | skill_manage(action='create'/'patch'/'edit') |
The adapted version lives at ~/.hermes/skills/devops/neat-freak/ with both original references (for understanding upstream platform differences) and Hermes-specific instructions. The core five-step logic is unchanged — only the tool calls were translated.
Installation
For Claude Code, Codex, or OpenCode:
npx skills add https://github.com/kkkkhazix/khazix-skills --skill neat-freak -g -y
For Hermes Agent, the adapted version is already available in the skills directory. To trigger it:
/neat
/ sync
同步一下
整理文档
sync up
Conclusion
The dirty secret of AI-assisted development is that your agent is only as smart as the documentation it reads. Code evolves at the speed of keystrokes; documentation evolves at the speed of human memory — which is to say, it usually doesn't.
neat-freak doesn't try to automate documentation from scratch. It takes a more practical approach: given a development session that just happened, make sure everything the agent now knows is reflected everywhere it should be. It's maintenance, not magic. But in a world where "I'll update the docs later" translates to "I will never update the docs," a maintenance tool that actually runs is more valuable than a generation tool that sits unused.
Run /neat after your next session. Your future self — and your future agent — will thank you.