Skill Graphs 2.0: A Tiered Architecture for AI Agent Skill Management
AI agent "skills" are having their npm moment. Every agent platform now ships with a skill system — Hermes, Claude Code, Codex, OpenCode. Install a skill from the hub. Write a few lines of frontmatter. The agent suddenly knows how to deploy a Docker container, search arXiv, or compose a song.
But as your skill library grows, a flat directory of markdown files breaks down. How do you know which skill depends on which? What happens when a bug fix in one skill silently breaks a downstream workflow? Why does an atom designed for blog deployment keep getting loaded for code review tasks?
This is where Skill Graphs 2.0 comes in. It is a methodology, not a tool — a way to organize skills into a composable, versioned, dependency-aware graph. We have applied it across nearly 200 personal skills spanning eight domains. Here is what we learned.
The Problem With Flat Skills
Most agent skill systems share a simple model: a directory of SKILL.md files, each with a frontmatter block describing what the skill does and when to load it. The agent scans the directory at startup, builds an index, and loads relevant skills when a user request matches.
This works beautifully for 20 skills. At 100, it gets noisy. At 200, you start noticing problems:
- Unintended triggers. A skill written for blog deployment gets loaded during a code review. Its instructions — "run Docker build, verify 200, git commit" — don't make sense, but the agent reads them anyway.
- Silent chain breaks. Skill A calls Skill B, which was refactored last week and now expects different parameters. The agent loads B's new instructions but A's old workflow, producing mixed behavior.
- Missing dependency enforcement. A "blog quality gate" skill should always include a diagram assessment check. But nothing in the system enforces this. The author forgets. The gate passes with a gap.
- Discovery fatigue. 200 skills, 200 descriptions, 200 trigger patterns. The agent's matching algorithm returns the wrong subset half the time.
The root cause is that flat skills are documents, not components. They lack interfaces.
The Skill Graphs 2.0 Model
Skill Graphs 2.0 introduces four tiers, each with distinct semantics:
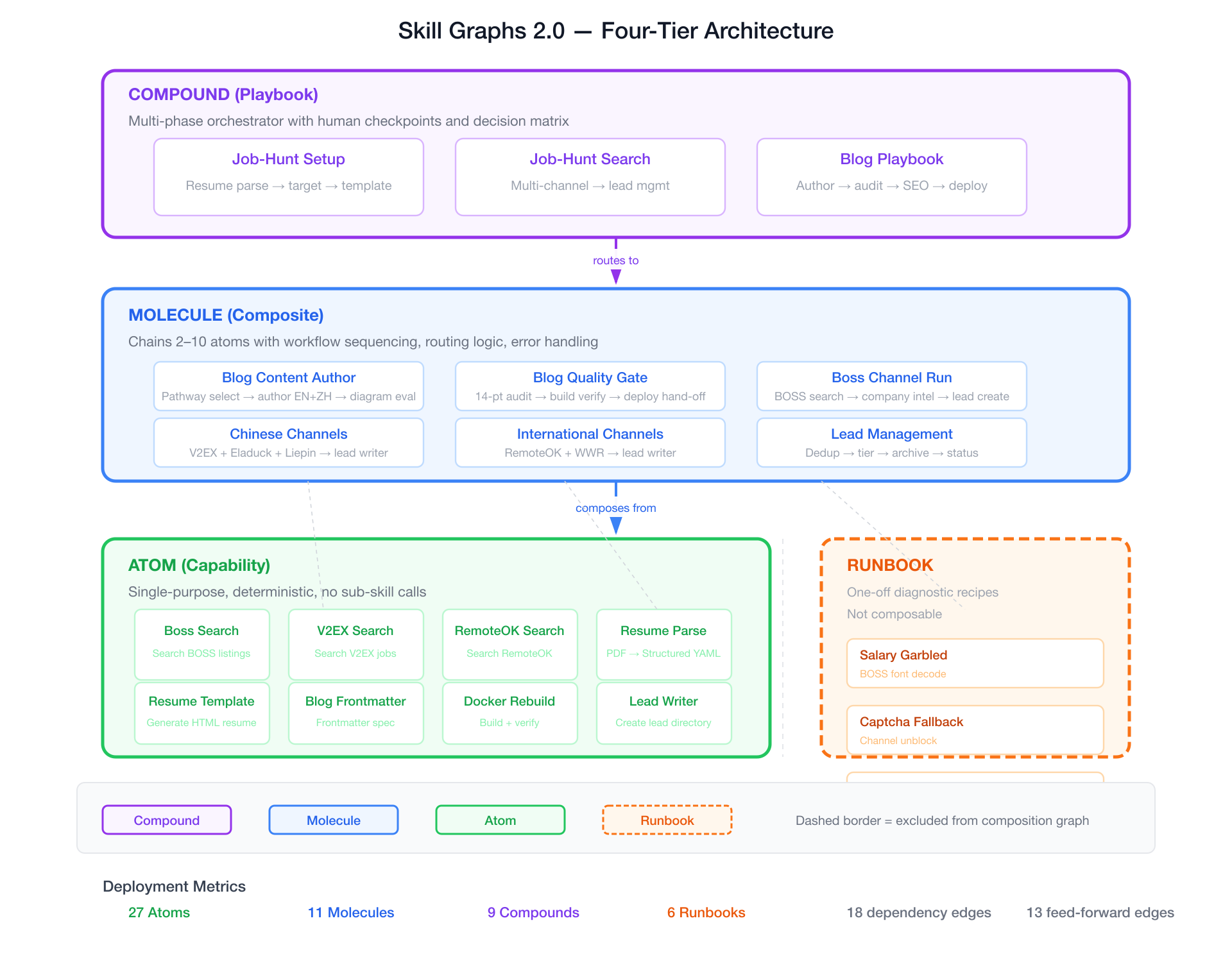
┌─────────────────────────────────────────────┐
│ COMPOUND │
│ Multi-phase orchestrator with checkpoints │
│ skill_type: playbook │
│ ┌─────────────────────────────────────┐ │
│ │ MOLECULE │ │
│ │ Chains 2-10 atoms with workflow │ │
│ │ skill_type: composite │ │
│ │ ┌──────────┐ ┌──────────┐ │ │
│ │ │ ATOM │ │ ATOM │ │ │
│ │ │capability│ │capability│ │ │
│ │ └──────────┘ └──────────┘ │ │
│ └─────────────────────────────────────┘ │
│ ┌─────────────────────────────────────┐ │
│ │ RUNBOOK │ │
│ │ One-off bug-fix recipe │ │
│ └─────────────────────────────────────┘ │
└─────────────────────────────────────────────┘
Atoms: Leaf Nodes
Atoms are single-purpose, deterministic skills. They call no other skills. They exist to solve exactly one problem — search GitHub, parse a resume, extract a page's body text.
An atom's description must be precise about when to load and when to skip. The field is not a summary; it is a trigger contract.
Good: "Use when the user asks to search arXiv for papers. Triggers on 'arxiv', 'paper', 'literature', 'cite'. Do NOT load for general web search." Weak: "Helps search arXiv."
Atoms should also declare their output format — what the downstream consumer can expect. This makes them composable.
Molecules: Workflow Chains
Molecules chain 2-10 atoms (or other molecules) into a workflow with explicit instructions. They have a requires_skills field that declares what they depend on. The agent can validate the chain before executing: "I need blog-post-frontmatter, blog-pre-commit-audit, and blog-docker-rebuild. Are they all available?"
The molecule's SKILL.md does not repeat the atom's instructions. It describes sequencing, routing logic, and error handling:
### Phase 2: Quality Gate
Load `blog-quality-gate` via skill_view(name='blog-quality-gate').
Run the pre-commit audit. Phase 1.5 checks if diagrams were evaluated.
If diagram signals exist but no diagrams, block progress.
Molecules are where the dependency graph becomes visible. An atom with feeds_into: [blog-quality-gate] signals which workflows depend on it. A breaking change to the atom can be traced: check all skills in feeds_into for compatibility.
Compounds: Multi-Phase Playbooks
Compounds are the top-level orchestrators. They span multiple phases, include human checkpoints (via the clarify tool), and ship with a decision matrix — a table mapping user intent to execution path.
A compound might define three paths:
- Quick: just execute and commit, no audit
- Standard: full authoring + audit + SEO + deploy
- Deep: standard + post-publish codebase accuracy verification
Each path loads a different molecule at each phase. The compound does not repeat the molecule's instructions; it routes.
Runbooks: One-Off Diagnostics
Runbooks are excluded from the composition graph. Their skill_type: runbook signals that they solve a specific, bounded problem that should not be chained. They are indexed, searchable, and loadable — but never pulled as a dependency.
Examples: "Fix garbled salary encoding on BOSS直聘" or "Diagnose Docker restart loops in Django containers."
Metrics From a Real Deployment
We applied Skill Graphs 2.0 to a personal skill library totaling 194 skills across 8 domains. Here are the numbers:
| Metric | Value |
|---|---|
| Total skills | 194 |
| Atoms (capability) | 27 |
| Molecules (composite) | 11 |
| Compounds (playbook) | 9 |
| Runbooks | 6 |
| Skills with explicit dependencies | 18 |
| Skills feeding into others | 13 |
| Skills with version tags | 112 |
| Total skill content | ~1.3 MB (34,000 lines) |
| Average skill size | ~176 lines |
Domain distribution:
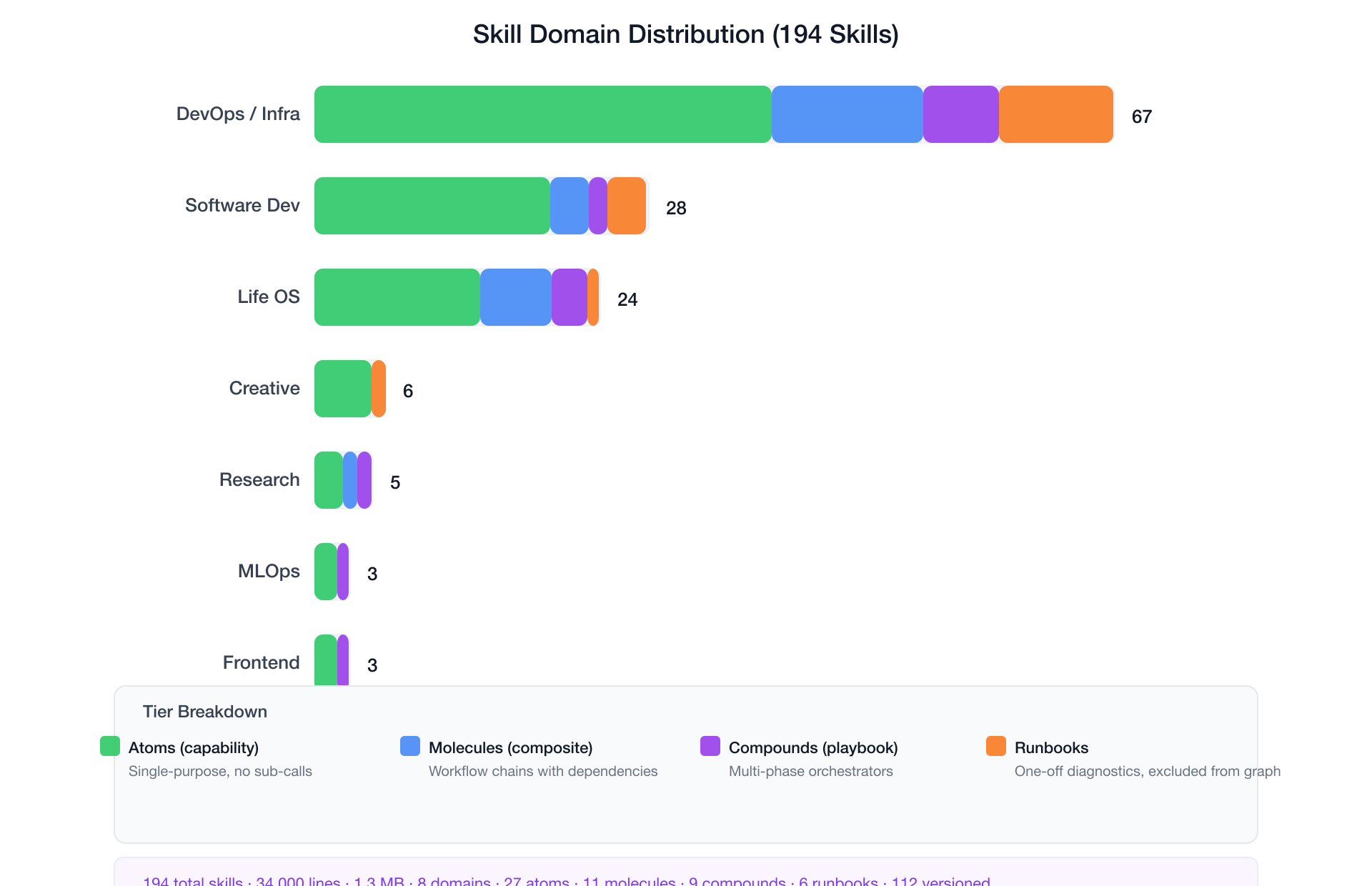
| Domain | Count |
|---|---|
| DevOps / Infrastructure | 67 |
| Software Development | 28 |
| Life OS (automation) | 24 |
| Creative / Design | 6 |
| Research | 5 |
| MLOps | 3 |
| Frontend Design | 3 |
| Others (security, docs, etc.) | 10+ |
The composition graph is modest — 18 dependency edges and 13 feed-forward edges. This is not a densely connected system. It is a shallow tree, where most atoms are independent, a handful of molecules bridge them, and a few compounds sit on top as entry points.
This shape is intentional. Dense graphs are fragile. Shallow trees with versioned leaves are resilient to change.
The 3-Layer Architecture
Beyond the skill graph itself, we implemented a three-layer architecture for managing skill provenance — who owns which skill, and how it syncs across machines.
Layer 1: BUILT-IN SKILLS
└─ Shipped with Hermes releases. Auto-managed. Never modify.
Layer 2: HUB-INSTALLED SKILLS
└─ Installed from the community hub via `hermes skills install`.
Tracked in a manifest file, not in git.
Reproducible: run the bootstrap script on a new machine.
Layer 3: PERSONAL SKILLS
└─ Self-built + forked. Lives in a git repo mounted via
external_dirs. Git push/pull for multi-machine sync.
The manifest (skills-manifest.yaml) records every hub skill with its source URL. A bootstrap script reads the manifest and reinstalls everything on a new machine. This means third-party skills stay updatable from their upstream while remaining reproducible — you do not fork them into your personal repo, you reference them.
The 3-layer separation also enforces a clean boundary: if a skill exists in Layer 3, it should not also exist in Layer 1 or 2. Duplicates create confusion about the source of truth. During our consolidation, removing overlaps shrank the personal repo by nearly 20,000 lines — skills that were built-in or hub-installed had been accidentally cloned.
What We Got Right
1. Description as Trigger Contract
The most impactful change was rewriting skill descriptions to be trigger contracts instead of summaries. A skill for "BOSS直聘 salary extraction" does not say "helps with salary problems." It says: "Use when BOSS直聘 salary text appears garbled due to font anti-crawl. Triggers on 'salary garbled', 'zhipin salary'. Do NOT load for general salary discussions."
This is a discipline, not a technology. But it works: the agent's matching precision improves dramatically when descriptions encode inclusion and exclusion rules.
2. Diagram Gate as a Hard Block
After discovering that diagram insertion was silently skipped across five consecutive blog posts (the chain had no hard requirement at any point), we patched four skills to add a mandatory assessment checkpoint. The molecule that orchestrates content authoring now includes Step 3: Diagram Suitability Assessment. The quality gate molecule includes Phase 1.5: check if the assessment was run. If diagram signals exist but no proposal was made to the user, the gate blocks progress.
This is a pattern worth internalizing: when you discover that nobody enforces X, distribute X across two skills. Make each independently responsible. The overlap ensures at least one will catch it.
3. Versioning as a Signal
112 of 194 skills carry explicit version numbers. The versions are semantic: 1.0.0 for initial release, 1.1.0 for feature additions, 2.0.0 for breaking changes. This is lightweight — a single line in the frontmatter — but it enables a crucial operation: when an atom is upgraded from 1.x to 2.x, you can grep for all molecules that depend on it and check their compatibility.
What We Would Do Differently
1. Test Harness for Skill Chains
We have no automated way to verify that "blog content authoring → blog quality gate → blog build deploy" still works end-to-end after a change to any atom in the chain. A dry-run mode — "simulate loading these skills, execute the chain with no side effects, report any breakage" — would catch silent breaks before they hit real sessions.
2. Trigger Collision Detection
With 194 skills, trigger phrase overlap is inevitable. Two skills both triggered by "deploy" — one for blog deployment, one for Django deployment. The agent loads both, and the instructions conflict. A static analysis tool that scans all descriptions for overlapping trigger phrases and flags collisions would reduce this noise.
3. Skill Usage Telemetry
Which skills are actually loaded in real sessions? Which are never triggered? Which trigger when they should not? Without telemetry, we operate on hunches. A lightweight observer — "this skill was loaded X times, matched Y queries, produced Z errors" — would guide refactoring and retirement decisions.
Why This Matters
The AI agent ecosystem is converging on skills as the primary extensibility mechanism. Every platform ships a hub. Every hub fills with markdown files. And every user, after installing their 50th skill, hits the same wall: this is just a directory of documents. It has no structure.
Skill Graphs 2.0 is an attempt to provide that structure. It is not a new format or a new tool. It is a set of conventions: tier your skills, declare your dependencies, version your releases, separate your provenance layers. The conventions are simple enough to apply to any agent platform. The benefits — discoverability, maintainability, chain integrity — scale with skill count.
If you maintain more than 30 agent skills, start tiering them. The graph reveals what the flat directory hides.
The 194-skill deployment described in this post runs on Hermes Agent with the skill-graph-2.0 skill library. The methodology is platform-agnostic and applies to any agent system with composable skill units.