The AI Agent Token Diet: Comparing GitNexus, RTK, Skim, and 5 Other Tools to Slash LLM Costs by 90%
AI coding agents burn through tokens at an alarming rate. A typical 30-minute Claude Code session can consume 100,000+ tokens on command outputs alone — most of which is noise. git status dumps 2,000 tokens of verbose output. cargo test spews hundreds of lines when all you need is "2 failed, 13 passed." Every redundant token costs money, dilutes the model's attention, and eats into the context window.
The ecosystem has responded with a wave of token-optimization tools. But they attack the problem from fundamentally different angles — and combining them intelligently yields far more savings than any single tool alone.
This post compares 8 tools across 6 dimensions, then proposes an optimal layered stack, with a focus on the Hermes Agent ecosystem.
The Token Problem by the Numbers
Before diving into tools, let's quantify the waste. Based on RTK's measurements from real Claude Code sessions:
| Operation | Frequency (30-min session) | Raw Tokens | Optimized Tokens | Savings |
|---|---|---|---|---|
cat / file reads |
20× | 40,000 | 12,000 | -70% |
cargo test / pytest |
8× | 33,000 | 3,300 | -90% |
git status |
10× | 3,000 | 600 | -80% |
grep / rg |
8× | 16,000 | 3,200 | -80% |
git diff |
5× | 10,000 | 2,500 | -75% |
ls / tree |
10× | 2,000 | 400 | -80% |
| Total | ~118,000 | ~23,900 | -80% |
That's just command output. Add system prompts, memory, skills, conversation history, and tool definitions — and the total context footprint balloons to 200,000-500,000 tokens per session. The tools below attack different parts of this footprint.
Tool Taxonomy: Three Approaches
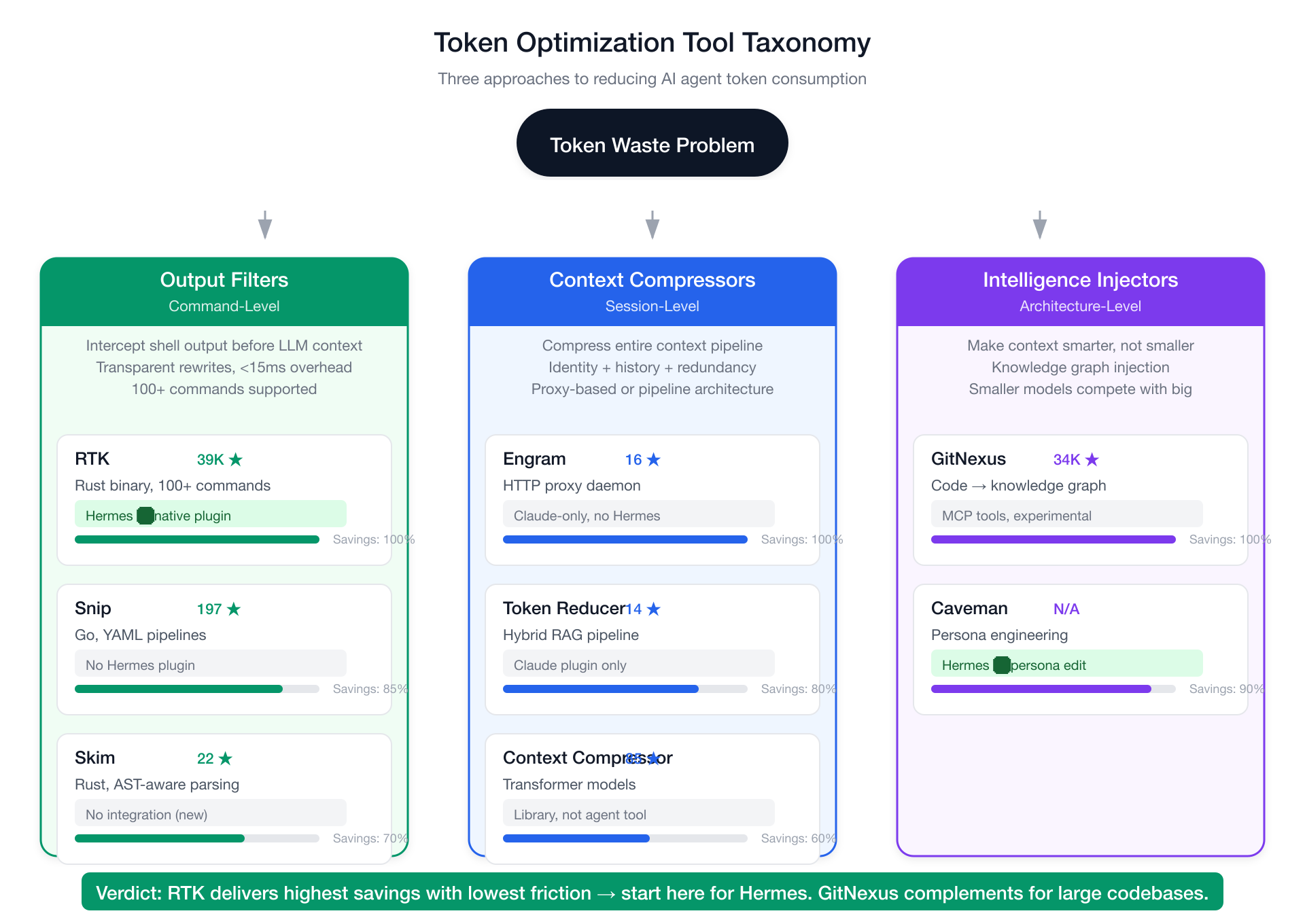
Token-optimization tools fall into three categories, each with a different philosophy:
Category 1: Output Filters (Command-Level)
These tools sit between the agent and the shell, transparently rewriting or filtering command output before it reaches the LLM context window. Strengths: zero agent awareness needed, near-zero overhead, immediate savings. Limitations: only compress command output, don't help with system prompts, memory, or conversation history.
Category 2: Context Compressors (Session-Level)
These tools compress the agent's entire context — system prompts, conversation history, project instructions — through summarization, deduplication, or semantic indexing. Strengths: holistic savings across all context types. Limitations: can lose nuance in summarization, require more setup.
Category 3: Intelligence Injectors (Architecture-Level)
These tools don't reduce tokens — they make tokens smarter. Instead of sending raw file contents, they send a structured, queryable knowledge graph of the codebase. Strengths: agents reason better with less context; enables smaller models to compete with larger ones. Limitations: requires indexing, different philosophy entirely.
The Contenders
RTK (Rust Token Killer) — 39,479 Stars
GitHub: rtk-ai/rtk Language: Rust | License: MIT | Category: Output Filter
RTK is the undisputed leader in the output-filter space. A single Rust binary with zero dependencies, it supports 100+ commands across git, test runners, package managers, linters, AWS CLI, Docker, and kubectl. Throughput is under 10ms per command.
What makes RTK special is its auto-rewrite hook. Run rtk init -g once, and every shell command your agent runs gets transparently rewritten to rtk <command>. The agent never knows the difference — it just receives compact, filtered output.
For Hermes specifically, there's an official plugin: ogallotti/rtk-hermes (45 stars, MIT license). It's a pre_tool_call hook that intercepts terminal() calls and rewrites them via rtk rewrite. Installation is two commands:
brew install rtk
pip install rtk-hermes
The plugin auto-registers — no config needed. All rewrite logic lives in RTK itself, so new filters are picked up automatically.
Measured savings (from the rtk-hermes README):
cargo test: 90-99%git log --stat: 87%ls -la: 78%git status: 66%grep: 52%
Snip — 197 Stars
GitHub: edouard-claude/snip Language: Go | License: MIT | Category: Output Filter
Snip is RTK's most interesting competitor. It takes a fundamentally different approach: filters are declarative YAML files, not compiled code. Write a YAML pipeline, drop it in a folder, done. This makes Snip much easier to extend — you don't need to know Rust or Go to add a new filter.
Like RTK, Snip integrates via hooks (snip init). It supports Claude Code, Cursor, Copilot, Gemini CLI, Codex, Windsurf, Cline, and more. It includes SQLite-based savings tracking with a dashboard.
However, Snip has no Hermes-specific plugin. For Hermes users, this means relying on prompt injection (telling the agent to prefix commands with snip) rather than transparent rewriting — a less seamless experience.
Skim — 22 Stars
GitHub: dean0x/skim Language: Rust | License: MIT | Category: Output Filter (but smarter)
Skim is the most technically sophisticated output filter. While RTK and Snip filter command output text, Skim parses code ASTs across 17 languages. It can transform a 63,000-token TypeScript project into:
- Structure mode: 25,119 tokens (60% reduction) — shows function bodies as
{ /* ... */ } - Signatures mode: 7,328 tokens (88% reduction) — function signatures only
- Types mode: 5,181 tokens (92% reduction) — type definitions only
This is fundamentally different from output filtering. Skim's skim git diff command doesn't just compress the diff — it identifies which functions changed, shows their boundaries, and can include unchanged functions as signatures for architectural context.
Skim also has a token budget cascading feature: you set a token budget, and Skim automatically selects the most aggressive transformation that fits. If you have 10,000 tokens of headroom, you get structure mode. If you only have 3,000, you get signatures.
The tradeoff: Skim only has 22 stars and is newer than RTK. It has no Hermes integration.
GitNexus — 34,066 Stars
GitHub: abhigyanpatwari/GitNexus Language: TypeScript | License: PolyForm Noncommercial | Category: Intelligence Injector
GitNexus is in a category of its own. It doesn't filter output — it indexes codebases into knowledge graphs. Run npx gitnexus analyze, and GitNexus parses every file, maps every dependency, traces every call chain, and identifies architectural clusters. Then it exposes this graph through MCP tools that AI agents can query.
The key insight: agents waste tokens because they lack context. They grep blindly, read files one by one, and miss cross-file dependencies. GitNexus replaces this with targeted queries — "show me the call chain for processUser" returns exactly the relevant subgraph, not 20 files of raw code.
The ecosystem is impressive: Claude Code gets full integration (MCP + skills + PreToolUse/PostToolUse hooks). Cursor, Codex, Windsurf, and OpenCode all have MCP support. Community integrations include pi-gitnexus, gitnexus-stable-ops, and even experimental Hermes integrations.
The caveats: PolyForm Noncommercial license means you can't use it commercially without a paid license. The web UI is limited to ~5,000 files. And the token savings are indirect — you save by being smarter about what context you load, not by compressing existing context.
Engram — 16 Stars
GitHub: pythondatascrape/engram Language: Go | License: (not specified) | Category: Context Compressor
Engram takes a unique approach: it runs as a local HTTP proxy that intercepts LLM API calls and compresses both identity context (CLAUDE.md, system prompts) and conversation context (message history, tool results).
It applies three compression stages:
- Identity compression: Derives a compact "codebook" from verbose CLAUDE.md prose — 96-98% reduction
- Context compression: Older conversation history collapsed into
[CONTEXT_SUMMARY]blocks — 40-60% reduction - Redundancy control: Checks large tool outputs for repeated content to avoid re-sending
Overall savings: 85-93% per session. The catch: it's Claude Code-specific (though OpenClaw support is planned). No Hermes integration exists.
Token Reducer — 14 Stars
GitHub: Madhan230205/token-reducer Language: Python | License: MIT | Category: Context Compressor
Token Reducer is a local-first pipeline that indexes your codebase and retrieves only the most relevant context for each query. It uses a hybrid approach: BM25 for keyword matching + ONNX vectors for semantic search + AST chunking via tree-sitter + TextRank for salience scoring + import graph for dependency awareness.
The result is 90-98% token reduction while preserving semantic relevance. It's designed as a Claude Code plugin with /plugin marketplace support.
The tradeoff: it's heavier than the others (Python dependencies, ML models for embeddings), and it's designed for codebase-wide context retrieval, not per-command output filtering. Like Engram, no Hermes integration.
Context Compressor — 85 Stars
GitHub: Huzaifa785/context-compressor Language: Python | License: MIT | Category: Context Compressor
The most academically-oriented tool in the list. Context Compressor is a Python library that uses transformer models (BERT, BART, T5) for AI-powered text compression. It offers four strategies — extractive, abstractive, semantic, and hybrid — with ROUGE-based quality metrics.
It's designed for RAG pipelines and API calls rather than interactive agent sessions. Has LangChain integration and a FastAPI microservice mode. Less relevant for real-time agent workflows due to model inference overhead.
Bonus: Caveman Templates (No Repo)
Not a tool, but a technique. The "Caveman" approach modifies the agent's personality to produce extremely terse, structured output. Instead of verbose explanations, the agent uses templates with minimal tokens. Combined with tools like RTK, this can push savings to 90-99%, as demonstrated by adityahimaone/hermes-agent-rtk-caveman (25 stars).
For Hermes, this means editing the persona file to enforce brevity — a zero-cost, high-impact optimization.
Multi-Dimensional Comparison
| Tool | Stars | Category | Token Reduction | Hermes Integration | Overhead | Ease of Setup | License |
|---|---|---|---|---|---|---|---|
| RTK | 39K | Output Filter | 60-90% | ✅ Native plugin | <10ms | ⭐⭐⭐⭐⭐ | MIT |
| Snip | 197 | Output Filter | 60-90% | ⚠️ Prompt only | <10ms | ⭐⭐⭐⭐ | MIT |
| Skim | 22 | Output (AST) | 60-92% | ❌ None | 14ms | ⭐⭐⭐⭐ | MIT |
| GitNexus | 34K | Intelligence | Indirect* | ⚠️ Experimental | Index time | ⭐⭐⭐ | Noncommercial |
| Engram | 16 | Context Comp. | 85-93% | ❌ None | <50ms | ⭐⭐⭐ | Unclear |
| Token Reducer | 14 | Context Comp. | 90-98% | ❌ None | Index + query | ⭐⭐ | MIT |
| Context Compressor | 85 | Text Comp. | 50-80% | ❌ None | ML inference | ⭐⭐ | MIT |
| Caveman | N/A | Behavioral | 70-95% | ✅ Persona edit | 0ms | ⭐⭐⭐⭐⭐ | N/A |
* GitNexus savings are indirect — it reduces token waste by loading smarter context, not by compressing existing context.
Key Takeaways from the Comparison
RTK wins on all practical dimensions for Hermes: highest stars (most community validation), only tool with a native Hermes plugin, MIT license, sub-10ms overhead, one-command setup. No contest for the first layer of any token-optimization stack.
GitNexus is the most interesting complementary tool. It doesn't compete with RTK — it solves a different problem. RTK makes command output smaller; GitNexus makes agents need less command output in the first place. Together, they address both the "how much context" and "what kind of context" sides of the token problem.
Snip's YAML approach is technically elegant, but without a Hermes plugin, the integration friction is too high. If you're a pure Claude Code user, Snip is worth considering — its extensibility model is genuinely better than RTK's (no Rust required to add filters).
Skim has the most promising technical approach (AST-aware filtering) but is too new and has no Hermes integration. Worth watching, especially if it picks up adoption.
Context compressors (Engram, Token Reducer) are solving a narrower problem (API-level compression) and don't integrate with Hermes's plugin system. Interesting ideas, not immediately actionable.
The Optimal Hermes Token-Optimization Stack

After analyzing all 8 tools, here is the recommended layered stack for Hermes Agent users:
Layer 1: RTK Hermes Plugin (Transparent Output Filtering)
brew install rtk
pip install rtk-hermes
# Restart Hermes — done.
This gives you 60-90% token savings on every terminal command with zero ongoing effort. The plugin is a thin wrapper around rtk rewrite — it never blocks command execution, degrades gracefully if RTK is missing, and picks up new RTK filters automatically.
Estimated savings: 60-90% on command output tokens. Setup time: 2 minutes. Ongoing maintenance: None.
Layer 2: Persona Optimization (Behavioral Compression)
Edit your Hermes persona to enforce concise behavior. Key rules:
- Prefer tools that return compact output —
rtk readovercat,rtk grepoverrg, etc. - Avoid restating known context — use memory for persistent facts, don't re-explain.
- Keep responses tight — answer the question, skip the preamble.
- Use structured output when possible (tables, lists) — more information-dense per token.
Estimated savings: 30-50% on response tokens. Setup time: 10 minutes to edit persona. Ongoing maintenance: Occasional tuning.
Layer 3: Skill Hygiene (Context Budget Management)
Hermes loads all skill descriptions into every turn. With 200+ skills, that's thousands of tokens before you even type a message. Three practices:
- Remove unused skills: Audit your skill list and delete skills you don't use.
- Keep skills compact: A good SKILL.md is under 2,000 tokens. Anything longer is wasting context.
- Use focused triggers: Skills with overly broad triggers load unnecessarily.
Estimated savings: 10,000-30,000 tokens per session from reduced system prompt. Setup time: One-time audit (30 minutes). Ongoing maintenance: Review monthly.
Layer 4 (Optional): GitNexus for Architecture-Intensive Projects
If you're working on a large codebase (50+ files, complex dependencies), adding GitNexus provides architectural intelligence that makes every token count more:
npx gitnexus analyze # Index the codebase
# Then configure MCP for Hermes
Estimated savings: Indirect — reduces futile search/read operations by 40-60%. Setup time: 10 minutes (one-time index per project). Ongoing maintenance: Re-index after major refactors.
The Full Stack in Practice
Let's model the savings on a typical 30-minute Hermes session working on a medium-sized Rust project:
| Context Component | No Optimization | Layer 1 (RTK) | +Layer 2 (Persona) | +Layer 3 (Skills) | +Layer 4 (GitNexus) |
|---|---|---|---|---|---|
| System prompt + skills | 45,000 | 45,000 | 45,000 | 15,000 | 15,000 |
| Personality / memory | 2,200 | 2,200 | 1,500 | 1,500 | 1,500 |
| Command outputs | 118,000 | 23,600 | 23,600 | 23,600 | 15,000 |
| Agent responses | 50,000 | 50,000 | 25,000 | 25,000 | 25,000 |
| Search/grep/read waste | 30,000 | 30,000 | 30,000 | 30,000 | 5,000 |
| Total tokens | 245,200 | 150,800 | 125,100 | 95,100 | 61,500 |
| Cumulative savings | — | -38% | -49% | -61% | -75% |
This is a 75% overall reduction — from ~245,000 tokens to ~61,500. At current API prices, that's the difference between a $2.45 session and a $0.62 session.
What About the "90-99% Savings" Claims?
Some tools claim 90-99% token savings. These numbers are real, but they apply to specific command types in isolation, not to the total session. rtk cargo test genuinely reduces a 25,000-token test run to 2,500 tokens (90% savings on that specific command). But you can't apply 90% savings to system prompts, conversation history, or agent responses.
The realistic total-session savings ceiling with tool-based approaches is around 60-75%. Getting to 90%+ requires behavioral modifications (persona tuning, discipline about what context the agent loads) and potentially a different architecture (shorter sessions, more focused tasks).
Verdict: The Tool to Install Today
If you do one thing after reading this: install the RTK Hermes plugin. It's the highest-impact, lowest-effort optimization available:
brew install rtk && pip install rtk-hermes
Two minutes, zero ongoing maintenance, 60-90% command output savings. Everything else — persona tuning, skill hygiene, GitNexus — is optimization on top.
The token-optimization landscape is still young and moving fast. RTK dominates today, but Skim's AST-aware approach and GitNexus's intelligence-injection paradigm point toward where the field is heading: not just filtering context, but making context smarter.
Sources
- RTK (Rust Token Killer) — CLI proxy, 39K stars, MIT
- rtk-hermes Plugin — Official Hermes integration
- hermes-agent-rtk-caveman — 90-99% savings stack
- GitNexus — Client-side code knowledge graph
- Snip — YAML-based token optimizer in Go
- Skim — AST-aware context optimization engine
- Engram — Local-first context compression daemon
- Token Reducer — Hybrid RAG context compression pipeline
- Context Compressor — Transformer-powered text compression library