洁癖 neat-freak:让你的 AI Agent 不再「脑腐」的那个 Skill
你的 AI Agent 刚刚帮你重构了五个 API 路由,新增了三个环境变量,并把数据库从 SQLite 迁移到 PostgreSQL。代码很漂亮,测试全绿,你心情不错。
一周后,你打开一个新的会话。Agent 自信满满地建议你调用 deprecated_legacy_endpoint——因为 CLAUDE.md 里还写着这个接口。它尝试连接 SQLite——那是你七天前已经删掉的数据库。它完全不知道 REDIS_URL 已经被重命名为 CACHE_URL。
这不是模型的幻觉。这是文档的脑腐(brain rot)。而它是 AI 辅助开发中最被低估的问题之一。
AI Agent 生产力的隐形杀手
在传统的开发者工作流里,文档滞后虽然烦人,但还不致命。人类会扫一眼过时的文档,翻个白眼,然后直接 grep 代码库。但 AI Agent 是_逐字阅读_文档并且_完全信任_它的内容。当代码和文档之间的鸿沟越来越大,Agent 就会越来越笨——不是因为模型性能下降了,而是因为它所汲取的知识基底已经馊了。
这个问题是结构性的。原因如下:
- 代码变得快,往往一次会话就改好几轮
- CLAUDE.md / AGENTS.md 本应手动更新,但几乎没人记得
- docs/ 目录是给人看的,而人会忘记更新
- Agent 记忆在累积垃圾:相对时间戳("昨天"、"最近")、从未清理的已完成待办、以及来自不同会话的矛盾事实
每一层都是一个独立的体系,面向不同的受众。只修一层,其他层继续腐烂。而每次会话结束后手动去对齐——繁琐到几乎没人能做到。
洁癖 neat-freak 来了
neat-freak(洁癖)是 AI 领域头部自媒体「数字生命卡兹克」开源的一个 Agent Skill,其 GitHub 仓库已获得 7,700+ stars。它的设计思路很直接:在一次开发会话结束后,用 /neat、/sync 或"整理一下"等自然语言触发,然后系统性地将本次会话涉及的所有变更同步到三层项目知识体系中去。
neat-freak 与一个简单的"记得更新 CLAUDE.md"提醒的区别在于:它把自己当成编辑,而不是记录员。它不会往后追加,而是审视、合并、修正、删除。
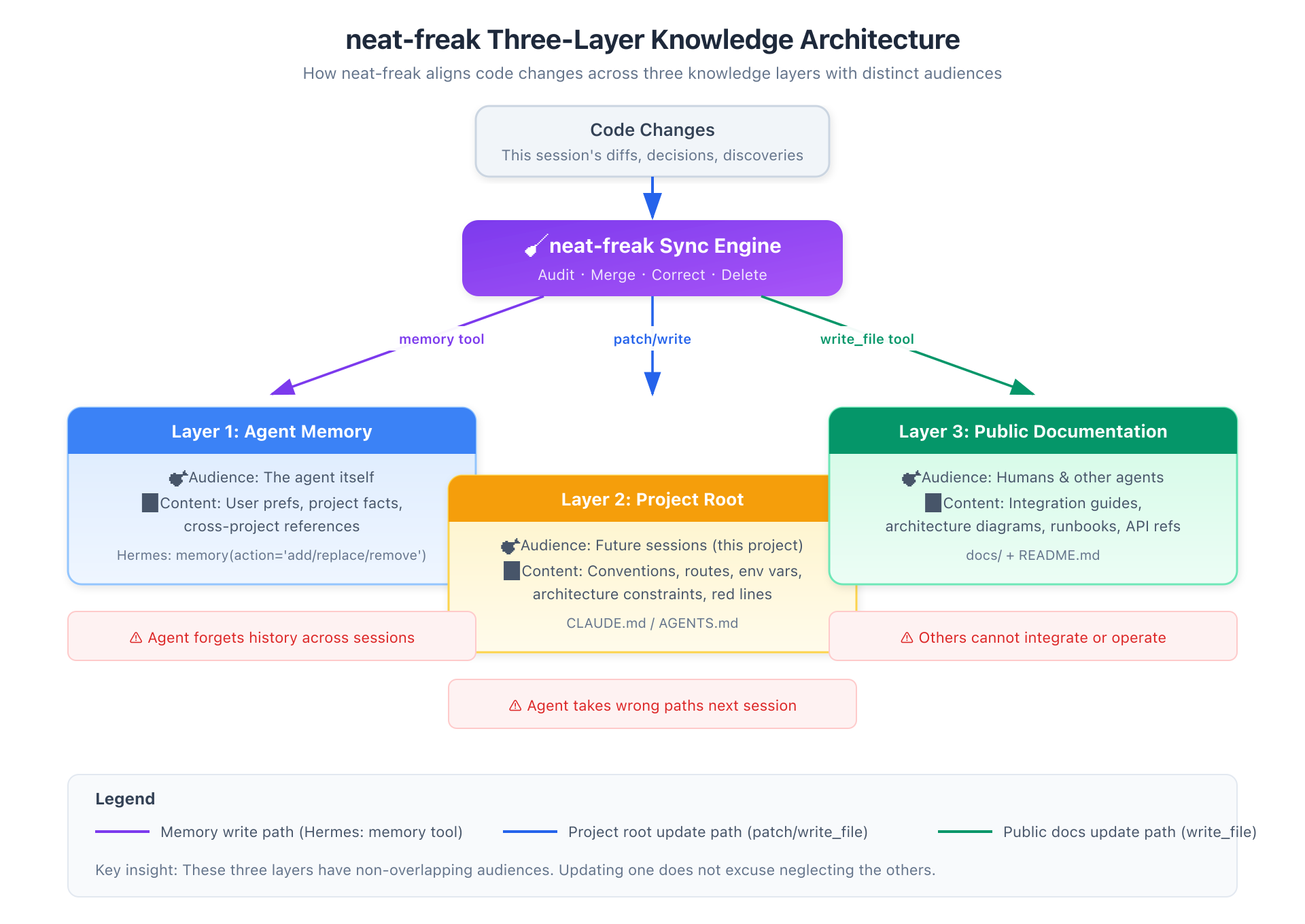
三层知识模型
neat-freak 的架构建立在一个清晰的关注点分离之上:
| 层级 | 位置 | 受众 | 职责 |
|---|---|---|---|
| Agent 记忆 | 平台相关(Claude: ~/.claude/projects/.../memory/,Hermes: memory 工具) |
Agent 自己,跨会话复用 | 用户偏好、非显而易见的项目事实、跨项目参考 |
| 项目根标识 | CLAUDE.md / AGENTS.md |
下次会话在这个项目里的 Agent | 项目约定、架构约束、环境变量表、路由清单 |
| 公共文档 | docs/ + README.md |
人类同事、下游开发者、未来其他平台的 Agent | 接入指南、架构图、运维手册、API 参考 |
关键洞见:这三层的受众不同,职责不重叠。在 CLAUDE.md 里写"新增了 device flow 五个路由"和在 docs/integration-guide.md 里写"下游怎么接这套 flow"是完全不同的两件事。前者是提醒明天的自己,后者是教会明天的同事。两份都要写。
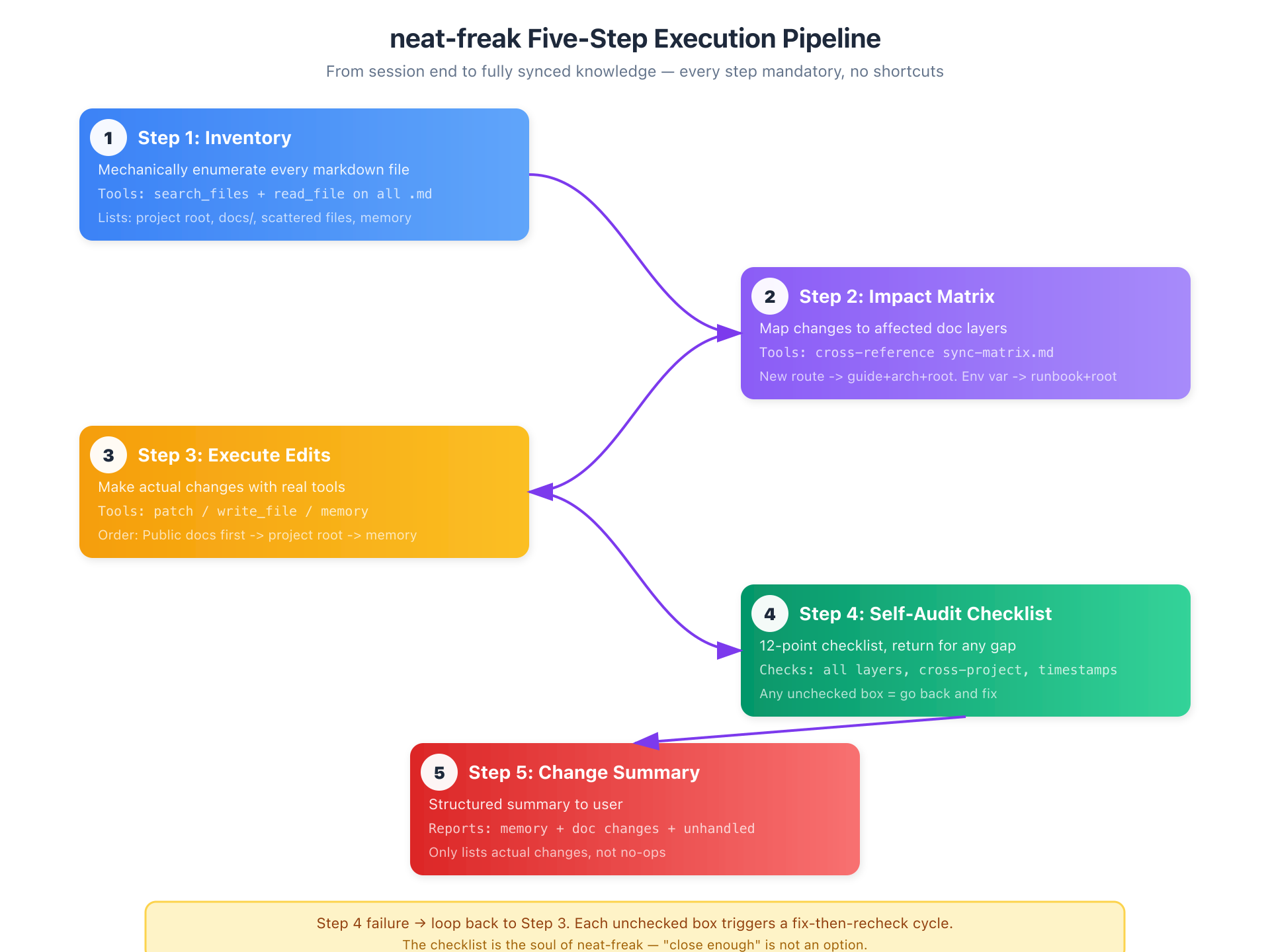
五步执行流程
触发后,neat-freak 执行一套严谨的五步流程:
第一步:盘点现状。 机械式枚举项目中的每一个 markdown 文件——根目录、docs/、散布的 .md、Agent 记忆文件——全部读一遍。不做假设,不走捷径。缺失的文件要确认,不能忽略。
第二步:变更影响矩阵。 这是 neat-freak 的智力核心。它不问"对话产生了哪些新事实",而是问"这些新事实会波及哪些文档层级"。它维护一张映射表:
- 新增 API 路由 → CLAUDE.md 路由清单 + 集成指南 + 架构文档
- 环境变量变更 → CLAUDE.md 环境变量表 + runbook + 下游集成文档
- 数据库 schema 变更 → CLAUDE.md + 架构文档的 Data Model
- 跨项目 API 变更 → 上游文档 + 下游文档(翻车重灾区!)
- 记忆清理 → 相对时间转绝对日期、合并重复、删除已完成待办
第三步:实际修改。 neat-freak 不只是描述"应该怎么改"——它真的去改。用平台的编辑工具逐个修改文件、创建新文件、删除过时内容。顺序很讲究:先改公共文档(对外部影响最大),再改项目根 markdown,最后整 Agent 记忆。
第四步:自检清单。 12 个检查点防止最常见的翻车:"我更新了 CLAUDE.md,应该完了吧?"每个集成指南都更新了吗?所有相对时间都去除了吗?跨项目改动时下游的文档也改了吗?任何一项打不了勾,就回去补。这不是建议——这是 neat-freak 之所以叫"洁癖"的原因。
第五步:变更摘要。 给用户一份结构化的总结:记忆层面改了什么,文档层面改了什么(按项目分组),以及哪些事情因为没有足够信息而留待用户确认。只列真正有变更的,没改的不写。
横向对比:为什么不只是用 AutoDream?
Claude Code 内置了一个叫 AutoDream 的功能,会在会话结束后自动更新 Agent 记忆。方向是对的,但它只操作一个层:Agent 的内部记忆。它不动 CLAUDE.md,不动 docs/,不处理跨项目影响。
如果你只用 Claude Code 而且项目都是单人维护的孤岛,AutoDream 可能够用。但一旦有同事需要理解你的系统,或者下游服务需要更新后的集成文档,这个差距就会变得肉眼可见且代价高昂。
neat-freak 还刻意做了跨平台设计。同一份 SKILL.md 文件在 Claude Code、OpenAI Codex、OpenCode、OpenClaw 上都能用。(我们也为 Hermes Agent 做了适配——见下文。)
我的多角度评估
在采纳 neat-freak 之前,我做了五个维度的评估:
| 维度 | 评分 | 理由 |
|---|---|---|
| 填补真实空白 | ★★★★★ | 没有人系统性地在会话后同步三层知识。这是真的没被解决的问题。 |
| 来源可信度 | ★★★★☆ | 7,733 stars、1,158 forks,作者有公开讲解文章。安装量(300)偏低但 GitHub 信号足以弥补。 |
| 跨平台可移植性 | ★★★★☆ | 按开放 Agent Skill 规范设计,概念模型跨平台通用,只需映射工具绑定。 |
| 工作流整合 | ★★★★☆ | 五步流程足够系统化以保证可靠性,又足够灵活以适应非常规项目结构。 |
| 误触发风险 | ★★★☆☆ | "整理一下"、"tidy up"这类自然语言触发词可能在不该触发时触发,但第一步(盘点)是只读的,误触发也无害。 |
最大的采纳风险是纪律性:neat-freak 只有在你真的跑它的时候才有用。但相比于每次非 trivial 的会话结束后手动审三层文档——它是巨大的时间节省和质量保障。
Hermes Agent 适配
我使用 Hermes Agent 作为主要的 AI 编程环境,所以需要把 neat-freak 的工具绑定做一次适配。原版 skill 假设的是 Claude Code 的基于文件的记忆系统(~/.claude/projects/.../memory/MEMORY.md)及其原生编辑工具。
以下是我做的 Hermes 映射:
| 原版概念 | Hermes 等价 |
|---|---|
| Claude 记忆文件 | memory 工具(add/replace/remove) |
| 用户偏好 | memory(target='user') |
| 文件编辑 | patch / write_file 工具 |
| 跨会话回溯 | session_search |
| 技能管理 | skill_manage(action='create'/'patch'/'edit') |
适配版位于 ~/.hermes/skills/devops/neat-freak/,同时保留了原版参考文件(用于理解上游平台差异)和 Hermes 专用指令。核心的五步逻辑没变——只翻译了工具调用。
安装方式
Claude Code / Codex / OpenCode 用户:
npx skills add https://github.com/kkkkhazix/khazix-skills --skill neat-freak -g -y
Hermes Agent 用户:适配版已内置在 skills 目录中。触发方式:
/neat
/ sync
同步一下
整理文档
sync up
结语
AI 辅助开发中最不干净的那个秘密是:你的 Agent 只能聪明到它所读到的文档为止。代码以击键的速度演进,文档以人类记忆的速度演进——也就是说,通常它不动。
neat-freak 不试图从头生成文档。它选择了一个更务实的路径:给定一个刚刚发生的开发会话,确保 Agent 现在知道的一切,都出现在了它应该出现的每一个地方。这是维护,不是魔法。但在这个"稍后更新文档"等于"永远不会更新文档"的世界里,一个真正会跑的维护工具,比一个从来不会用的生成工具要值钱得多。
下次会话结束的时候,跑一次 /neat。未来的你——和未来的 Agent——会感谢现在的你。