Skill Graphs 2.0:AI Agent 技能的层级化架构设计方法论
AI Agent 的「技能」正在经历它们的 npm 时刻。现在几乎每个 Agent 平台都自带技能系统——Hermes、Claude Code、Codex、OpenCode。从 Hub 装一个技能,写几行 frontmatter,Agent 突然就会部署 Docker 容器、搜索 arXiv 论文、或者写歌词了。
但当你的技能库膨胀后,一个扁平的 markdown 文件目录会迅速失控。你怎么知道哪个技能依赖哪个?一个技能的 bug 修复会不会悄悄破坏下游工作流?为什么一个用于博客部署的原子技能,老是被代码审查任务加载?
这就是 Skill Graphs 2.0 要解决的问题。它不是工具,是方法论——一种将技能组织为可组合、可版本化、依赖感知的图谱的方法。我们在一套覆盖 8 个领域、近 200 个技能的实战体系中应用了它。以下是所得。
扁平技能的困境
大多数 Agent 技能系统共享一个简单模型:一个装满 SKILL.md 文件的目录,每个文件带一个 frontmatter 描述技能做什么、何时加载。Agent 启动时扫描目录,建索引,当用户请求匹配时加载相关技能。
这对 20 个技能来说完美。到 100 个就开始吵杂。到 200 个,问题集中爆发:
- 误触发。一个为博客部署写的技能在代码审查中被加载了。它的指令——「执行 Docker 构建,验证 200,git 提交」——毫无意义,但 Agent 照样读了。
- 静默断链。技能 A 调用技能 B,B 上周重构过,现在需要新参数。Agent 加载了 B 的新指令和 A 的旧流程,产生混合行为。
- 依赖缺失。一个「博客质量关卡」技能理应包括图表评估检查。但系统没有任何东西强制这一点。作者忘了。关卡通过,缺口留下。
- 发现疲劳。200 个技能、200 条描述、200 个触发模式。Agent 的匹配算法一半时间返回错误的子集。
根本原因:扁平技能是文档,不是组件。它们没有接口。
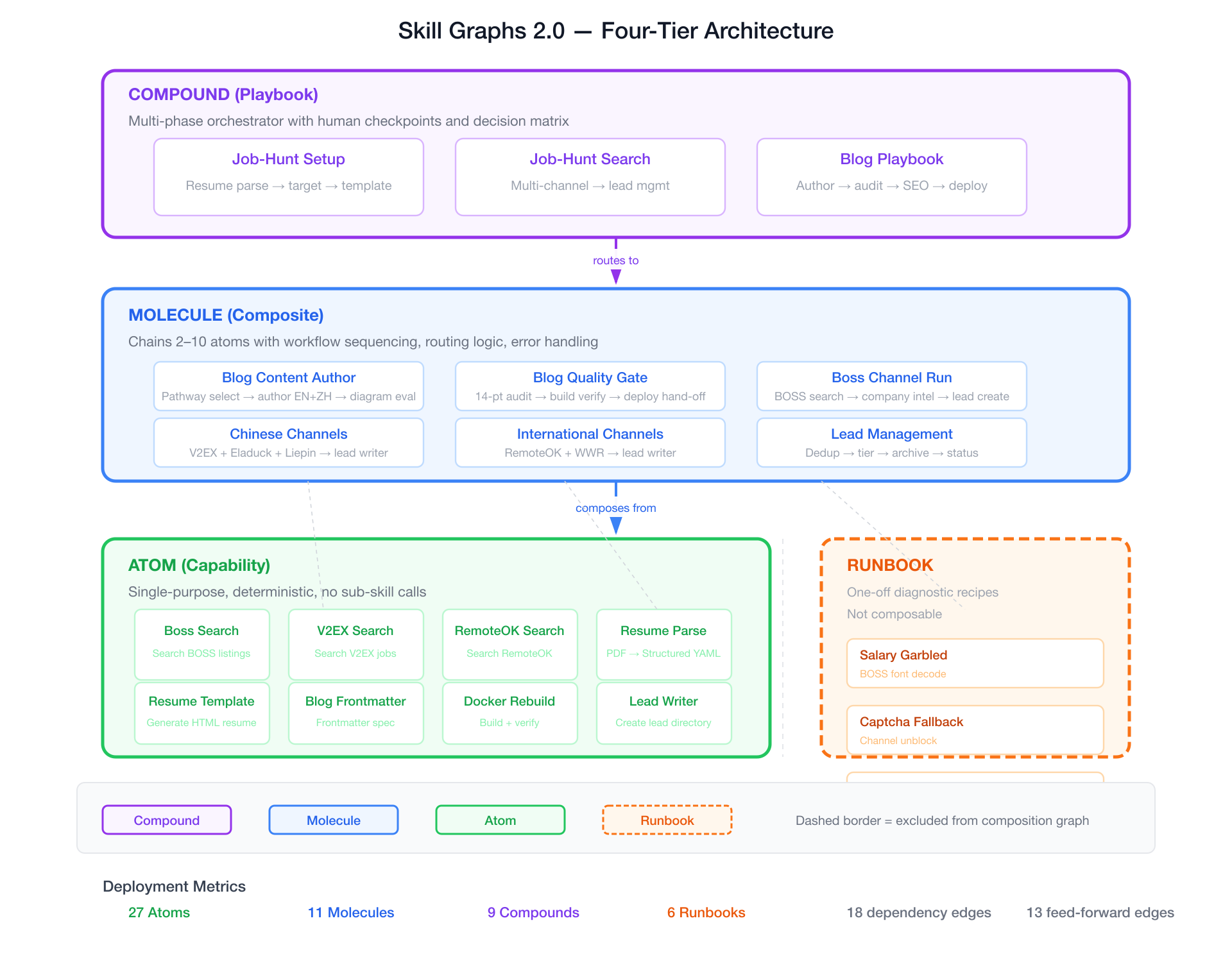
Skill Graphs 2.0 的四层模型
Skill Graphs 2.0 引入四个层级,每层有独特的语义:
┌─────────────────────────────────────────────┐
│ COMPOUND(化合物) │
│ 多阶段编排器,含人工检查点 │
│ skill_type: playbook │
│ ┌─────────────────────────────────────┐ │
│ │ MOLECULE(分子) │ │
│ │ 串联 2-10 个原子,有工作流 │ │
│ │ skill_type: composite │ │
│ │ ┌──────────┐ ┌──────────┐ │ │
│ │ │ATOM(原子)│ │ATOM(原子)│ │ │
│ │ │capability│ │capability│ │ │
│ │ └──────────┘ └──────────┘ │ │
│ └─────────────────────────────────────┘ │
│ ┌─────────────────────────────────────┐ │
│ │ RUNBOOK(操作手册) │ │
│ │ 一次性 bug 修复配方 │ │
│ └─────────────────────────────────────┘ │
└─────────────────────────────────────────────┘
原子:叶子节点
原子是单一用途、确定性的技能。不调用其他技能。只解决一个精确问题——搜索 GitHub、解析简历、提取页面文本。
原子的描述必须精确声明何时加载、何时跳过。这不是摘要,是触发合约。
好:「Use when the user asks to search arXiv for papers. Triggers on 'arxiv', 'paper', 'literature', 'cite'. Do NOT load for general web search.」 差:「Helps search arXiv.」
原子还应声明输出格式——下游调用者可以期望什么。这让它们可组合。
分子:工作流链
分子串联 2-10 个原子(或其他分子)为工作流,带有明确的步骤指令。它们有 requires_skills 字段声明自己的依赖项。Agent 可以在执行前验证链路:「我需要 blog-post-frontmatter、blog-pre-commit-audit 和 blog-docker-rebuild。它们都可用吗?」
分子的 SKILL.md 不会重复原子的指令。它描述顺序、路由逻辑和错误处理:
### Phase 2: Quality Gate
Load `blog-quality-gate` via skill_view(name='blog-quality-gate').
Run pre-commit audit. Phase 1.5 checks diagram evaluation.
If diagram signals exist but no diagrams, block progress.
分子层是依赖图谱变得可见的地方。一个原子带 feeds_into: [blog-quality-gate] 就标志了哪些工作流依赖它。对该原子的破坏性变更可以追踪:检查 feeds_into 中的所有技能是否兼容。
化合物:多阶段编排器
化合物是顶层调度器。它们跨越多阶段,包含人工检查点(通过 clarify 工具),并附有决策矩阵——将用户意图映射到执行路径的表格。
一个化合物可能定义三条路径:
- 快捷:只执行+提交,跳过审查
- 标准:完整创作+审计+SEO+部署
- 深度:标准+发布后代码库精确性验证
每条路径在每个阶段加载不同的分子。化合物不重复分子的指令;它只是路由。
操作手册:一次性诊断
操作手册被排除在编排图之外。其 skill_type: runbook 标记它解决一个特定的、有边界的问题,不应被链式调用。它们可索引、可搜索、可加载——但永远不会作为依赖被拉入。
示例:「修复 BOSS 直聘工资乱码」或「诊断 Django 容器的重启循环。」
来自实战部署的指标
我们在一个包含 194 个技能、横跨 8 个领域的个人技能库中应用了 Skill Graphs 2.0:
| 指标 | 数值 |
|---|---|
| 总技能数 | 194 |
| 原子(capability) | 27 |
| 分子(composite) | 11 |
| 化合物(playbook) | 9 |
| 操作手册(runbook) | 6 |
| 有显式依赖的技能 | 18 |
| 被其他技能依赖的技能 | 13 |
| 带版本号的技能 | 112 |
| 总内容量 | ~1.3 MB(34,000 行) |
| 平均技能大小 | ~176 行 |
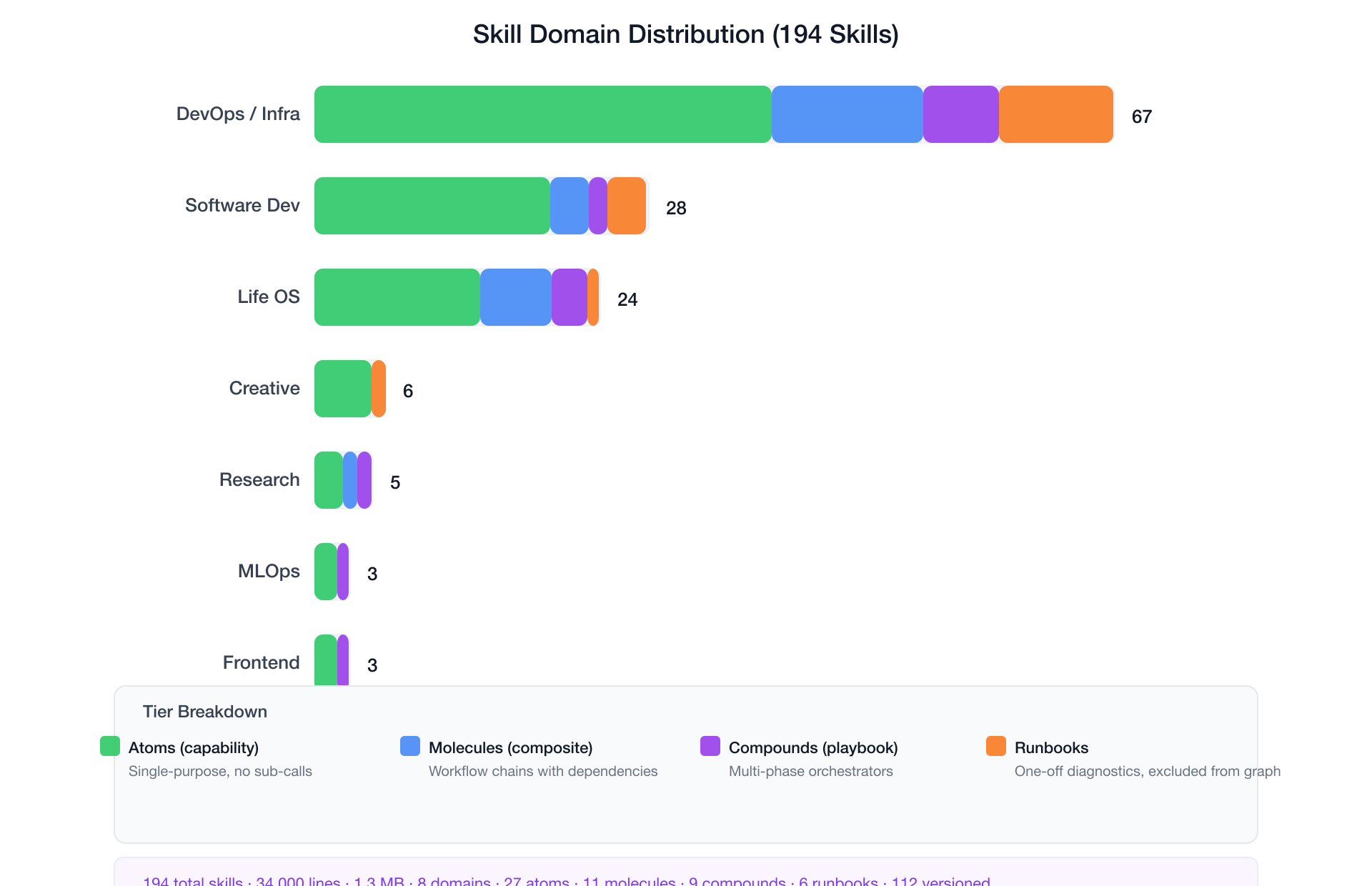
领域分布:
| 领域 | 数量 |
|---|---|
| DevOps / 基础设施 | 67 |
| 软件开发 | 28 |
| Life OS(自动化) | 24 |
| 创意 / 设计 | 6 |
| 研究 | 5 |
| MLOps | 3 |
| 前端设计 | 3 |
| 其他(安全、文档等) | 10+ |
编排图的规模适中:18 条依赖边和 13 条前馈边。这不是一个密集连接的系统,而是一棵浅树——大多数原子是独立的,少数分子桥接它们,几个化合物坐镇顶端作为入口。
这种形状是刻意的。密集图谱脆弱。带版本化叶子的浅树对变更具有韧性。
三层架构
在技能图谱之上,我们还实现了管理技能来源的三层架构——谁拥有哪个技能,以及如何在多台机器间同步。
Layer 1: BUILT-IN SKILLS
└─ 随 Hermes 版本发布。自动管理。永不修改。
Layer 2: HUB-INSTALLED SKILLS
└─ 从社区 Hub 通过 hermes skills install 安装。
通过 manifest 文件追踪,不放在 git 里。
可复现:在新机器上运行 bootstrap 脚本即可。
Layer 3: PERSONAL SKILLS
└─ 自建 + fork。放在 git 仓库中,通过 external_dirs 挂载。
git push/pull 实现多机同步。
manifest(skills-manifest.yaml)记录每个 Hub 技能及其来源 URL。bootstrap 脚本读取 manifest 并在新机器上重新安装一切。这意味着第三方技能保持可更新于上游、同时可复现——你不把它们 fork 进个人仓库,你引用它们。
三层分离也强制执行清晰的边界:如果一个技能存在于 Layer 3,它不应同时存在于 Layer 1 或 Layer 2。重复会造成真源混乱。在我们的整合过程中,移除重叠缩减了近 20,000 行——那些本属于内置或 Hub 安装的技能曾意外地被克隆进了个人仓库。
我们做对了什么
1. 描述即触发合约
最有影响的改变是将技能描述重写为触发合约而非摘要。一个「BOSS 直聘薪资乱码解析」技能不说「帮助处理薪资问题」,而是:「Use when BOSS直聘 salary text appears garbled due to font anti-crawl. Triggers on 'salary garbled', 'zhipin salary'. Do NOT load for general salary discussions.」
这是一种纪律,不是一种技术。但它有效:当描述编码了包含和排除规则时,Agent 的匹配精度大幅提升。
2. 图表关卡作为硬阻断
在发现图表插入在连续五篇博客中被静默跳过(链条中没有一个点有硬性要求)后,我们修补了四个技能以添加强制评估检查点。编排内容创作的分子现在包含 Step 3:Diagram Suitability Assessment。质量关卡分子包含 Phase 1.5:检查评估是否已运行。如果图表信号存在但未向用户提议,关卡阻断进度。
这是一个值得内化的模式:当你发现没人执行 X 时,把 X 分布到两个技能中。让每个独立负责。重叠确保至少一个会抓住它。
3. 版本化作为信号
194 个技能中有 112 个携带显式版本号。版本是语义化的:1.0.0 初始发布,1.1.0 功能新增,2.0.0 破坏性变更。这是轻量的——frontmatter 中的一行——但它使一个关键操作成为可能:当一个原子从 1.x 升级到 2.x 时,你可以 grep 所有依赖它的分子并检查兼容性。
如果重来
1. 技能链的测试工具
我们没有办法自动化验证「博客内容创作 → 博客质量关卡 → 博客构建部署」在对链中任何原子做变更后仍端到端工作。一个干跑模式——「模拟加载这些技能,在无副作用情况下执行链,报告任何断点」——能在真实会话前捕获静默断裂。
2. 触发碰撞检测
有 194 个技能,触发词组重叠不可避免。两个技能都被「deploy」触发——一个用于博客部署,一个用于 Django 部署。Agent 加载两者,指令冲突。一个扫描所有描述的触发词组并标记碰撞的静态分析工具能减少这种噪音。
3. 技能使用遥测
哪些技能在真实会话中被实际加载了?哪些从未触发?哪些触发了但不应触发?没有遥测,我们靠直觉运行。一个轻量观察器——「此技能被加载了 X 次,匹配了 Y 条查询,产生了 Z 个错误」——将指导重构和淘汰决策。
为什么这件事重要
AI Agent 生态系统正在汇聚于技能作为主要的扩展性机制。每个平台发布一个 Hub。每个 Hub 填满 markdown 文件。而每个用户,在安装了第 50 个技能后,都会撞到同一堵墙:这只是一个文档目录。它没有结构。
Skill Graphs 2.0 是提供这种结构的尝试。它不是新格式或新工具。它是一套约定:层级化你的技能,声明你的依赖,版本化你的发布,分离你的来源层。这些约定足够简单,适用于任何 Agent 平台。其收益——可发现性、可维护性、链完整性——随技能数量而放大。
如果你维护着超过 30 个 Agent 技能,开始层级化它们。图谱会揭示扁平目录藏匿的信息。