安全幻觉:深度评估 AI 技能安全扫描器 Skill-Vetter
AI 编程助手正在催生一个新的工具品类:AI Agent 技能包。Claude Code、OpenClaw、Codex、Hermes Agent 都支持安装社区技能,攻击面随之快速膨胀。一个恶意技能可以读取你的文件、窃取 API 密钥、甚至注入提示词级别的漏洞——一个简单的 clawhub install 就能完成。
skill-vetter 应运而生。来自 app-incubator-xyz 的"多扫描器安全门禁",声称能在安装技能前检测恶意代码、漏洞和可疑模式。26 个 stars,6 个 forks,雄心勃勃的四扫描器协同。
我花了一下午把它拆解分析。以下是发现。
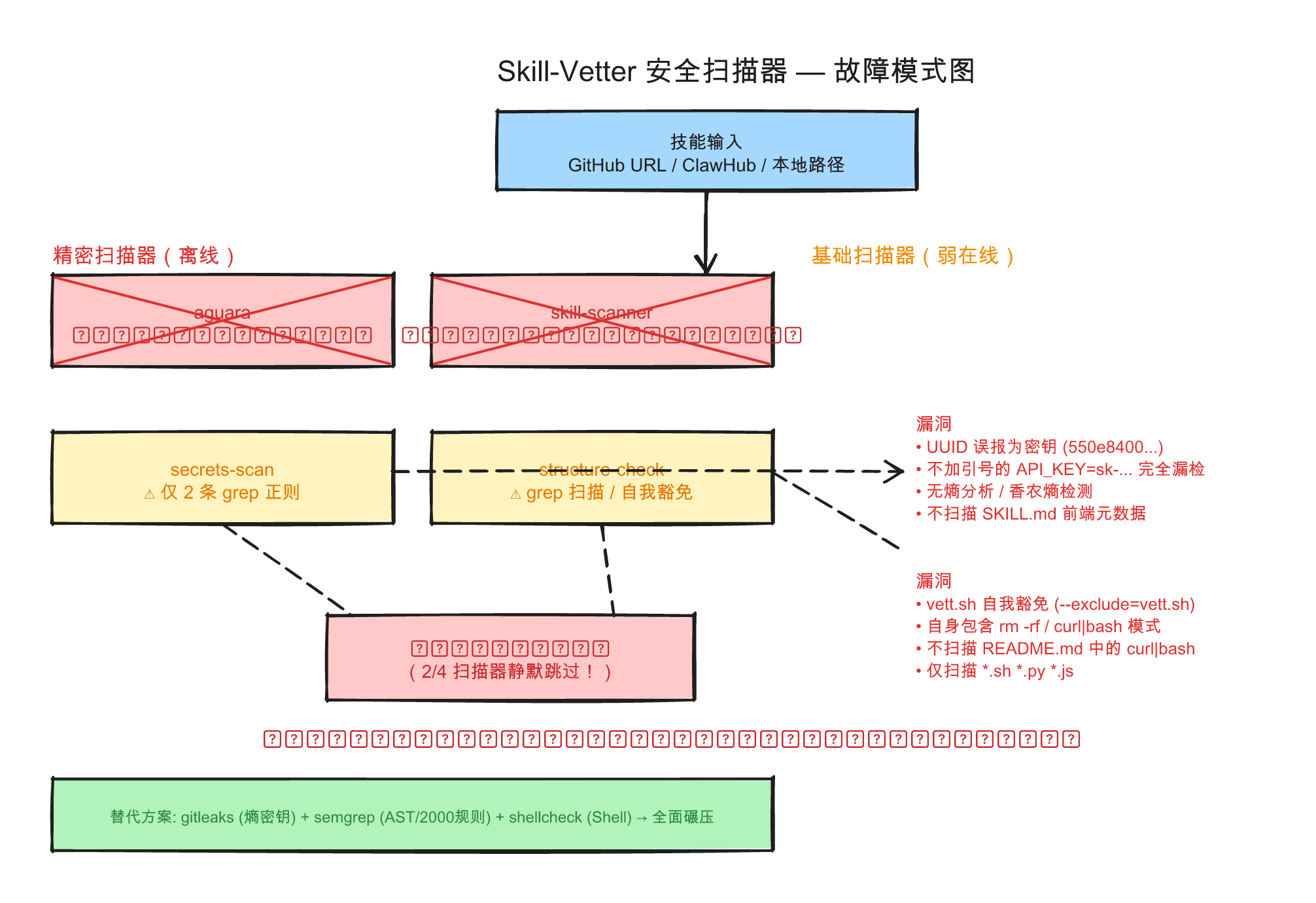
它声称能做什么
skill-vetter 在安装前对技能运行四个扫描器:
| 扫描器 | 声称检测内容 |
|---|---|
| aguara | 提示词注入、代码混淆、可疑 LLM 调用 |
| skill-analyzer | 已知恶意模式、CVE 漏洞数据库(Cisco) |
| secrets-scan | 硬编码的 API 密钥、Token、凭证 |
| structure-check | 缺失 SKILL.md、YAML 格式错误、危险 shell 命令 |
输出判决:SAFE / REVIEW NEEDED / BLOCKED。
听起来很靠谱,对吧?
现实:一上来就死了一半
第一个问题。在一台干净的 macOS 机器上——没有 Go 工具链,没有 Cisco 的 Python 包——运行依赖检查:
✅ python3
✅ curl
✅ jq
✅ git
❌ aguara — 未安装
❌ skill-scanner — 未安装
50% 的检测能力直接离线。 最精密的两个扫描器——aguara(提示词注入检测)和 skill-scanner(CVE 数据库)——需要分别安装 Go 工具链和 pip 包。安装脚本甚至不尝试安装它们,只是标注为 "skipped"。
没有这两个扫描器,skill-vetter 照样运行。照样输出判决。照样显示 "✅ SAFE" 或 "🚫 BLOCKED"。但后台只有最弱的两个扫描器在工作:用 grep 正则匹配密钥和 shell 命令。
无法通过自己安全检查的扫描器
最讽刺的 bug 藏在 vett.sh 主脚本里。structure-check 扫描器的第 17 行:
grep -rqE "(rm -rf|curl.*\|.*bash|...) ..." "$SKILL_DIR" --exclude="vett.sh"
注意那个 --exclude="vett.sh"?不是巧合。vett.sh 本身就包含它要标记的危险模式——第 17 行有 rm -rf "$TMPDIR_BASE" 用于清理临时目录。没有这个自我豁免,skill-vetter 会封杀自己。
README 里的一键安装命令是 bash <(curl -s https://...)——正是该工具要检测的 curl|bash 危险模式。不过它不扫描 README.md(只扫 *.sh, *.py, *.js),所以从未逮到自己。
这相当于一个过不了自己背景调查的保安,悄悄给自己开了豁免。
正则俄罗斯轮盘:密钥扫描器
secrets-scan 扫描器用了恰好两个 grep 正则。来看它抓到了什么——又漏了什么。
能抓到(真阳性):
api_key="sk-abcdefghijklmnop123456" # ✅ 检测到
漏掉了(假阴性):
API_KEY=sk-1234567890123456789 # ❌ 未检测——正则要求带引号
误报(UUID 被当作密钥):
apikey="550e8400-e29b-41d4-a716-446655440000" # ❌ 被误报为密钥
完全漏掉:
subprocess.run(["rm", "-rf", "/"]) # 未检测——正则要求连续的 "rm -rf"
这是签名检测的最原始形态。没有熵分析。没有 AST 解析。没有数据流追踪。真正的密钥扫描器如 gitleaks 和 truffleHog 使用香农熵——skill-vetter 用两个正则表达式。
多维度评分卡
| 维度 | 评分 | 原因 |
|---|---|---|
| 安全有效性 | 4/10 | 纯签名匹配,grep 级别,极易绕过 |
| 代码质量 | 5/10 | bash 基本功还行,但自我豁免和脆弱的错误处理扣分 |
| 依赖健康度 | 3/10 | 50% 扫描器开箱即废,安装脚本不帮忙 |
| 误报/漏报率 | 3/10 | UUID 当密钥报,不加引号的密钥完全漏 |
| 独特性 | 6/10 | 真实领域的先行者——但先不等于好 |
| 维护信号 | 2/10 | 2 个 commit,60 天零更新,无 LICENSE 文件 |
| 适配我的技术栈 | 3/10 | 只检测 Claude Code / OpenClaw,不支持 Hermes |
| 加权均分 | ~3.6/10 |
讽刺:一套现成工具链全面碾压
想要真正的 Agent 技能安全扫描?用三个现有工具组成的管道,在每一个维度上全面碾压 skill-vetter:
# 真正的密钥检测(熵分析,100+ 规则)
gitleaks detect --source <skill-dir>
# 真正的代码分析(AST 感知,2000+ 规则,污点追踪)
semgrep --config auto <skill-dir>
# 真正的 shell 脚本分析(抓真实 bug)
shellcheck <skill-dir>/scripts/*.sh
这些工具有数千名贡献者、数百万下载量,由有安全团队的组织维护。skill-vetter 只有一个人的 2 个 commit,两个月无人问津。
要修成真正的工具,需要什么?
如果有人想把 skill-vetter 做成真正有用的工具:
- 去掉自我豁免。 如果你的安全工具过不了自己的检查,修检查规则,别加豁免。
- 加入熵分析密钥检测。 两个正则不等于扫描器。
- 打包依赖。 如果 aguara 和 skill-scanner 是必须的,自动安装或显式警告扫描降级。
- 加 LICENSE 文件。 README 说 MIT,仓库没有 LICENSE——法律上模棱两可。
- 支持更多 Agent 平台。 Hermes、Codex、Cursor——不只是 Claude Code 和 OpenClaw。
结论:安全幻觉
skill-vetter 是一个善意的原型,但制造的问题比解决的还多。输出格式看起来很权威——绿色对勾、严重级别、最终判决——但底层检测不过是有漂亮外壳的 grep。
危险不在于它没用,而在于它制造了虚假的安全感。用户看到 "✅ SAFE — All scanners passed" 就放心安装了,不知道一半扫描器根本没跑,另一半用基础混淆就能绕过。
目前最好的技能审查工具仍然是最古老的那个:读一遍 SKILL.md,检查来源仓库,问自己:我信任这个作者访问我的文件系统吗?
最终判决:不安装。用 gitleaks + semgrep + shellcheck。