AI 编程 Agent Token 瘦身术:GitNexus、RTK、Skim 等 8 款工具深度横评 —— 如何砍掉 90% 的 Token 开销
AI 编程 Agent 正在疯狂吞噬 token。在一个典型的 30 分钟 Claude Code 会话中,仅命令输出就可能消耗超过 10 万 token,而其中大部分是噪音。git status 输出 2000 token 的冗长信息。cargo test 喷出几百行,但你需要的只是"2 个失败,13 个通过"。每个冗余 token 都在烧钱、稀释模型注意力、占据宝贵的上下文窗口。
生态圈迅速涌现了一批 token 优化工具。但它们解决问题的角度截然不同 —— 而将它们叠加使用,效果远胜任何单一工具。
本文对 8 款工具进行 6 维度横评,提出最优分层方案,重点聚焦 Hermes Agent 生态。
Token 浪费的数据画像
在深入工具之前,先量化浪费。基于 RTK 对真实 Claude Code 会话的测量:
| 操作 | 频率 (30分钟会话) | 原始 Token | 优化后 Token | 节省 |
|---|---|---|---|---|
cat / 文件读取 |
20× | 40,000 | 12,000 | -70% |
cargo test / pytest |
8× | 33,000 | 3,300 | -90% |
git status |
10× | 3,000 | 600 | -80% |
grep / rg |
8× | 16,000 | 3,200 | -80% |
git diff |
5× | 10,000 | 2,500 | -75% |
ls / tree |
10× | 2,000 | 400 | -80% |
| 合计 | ~118,000 | ~23,900 | -80% |
这还只是命令输出。加上系统提示词、记忆、技能、对话历史、工具定义 —— 整个上下文占用轻松突破 20-50 万 token/会话。下面的工具各自攻击不同环节。
工具分类学:三种路线
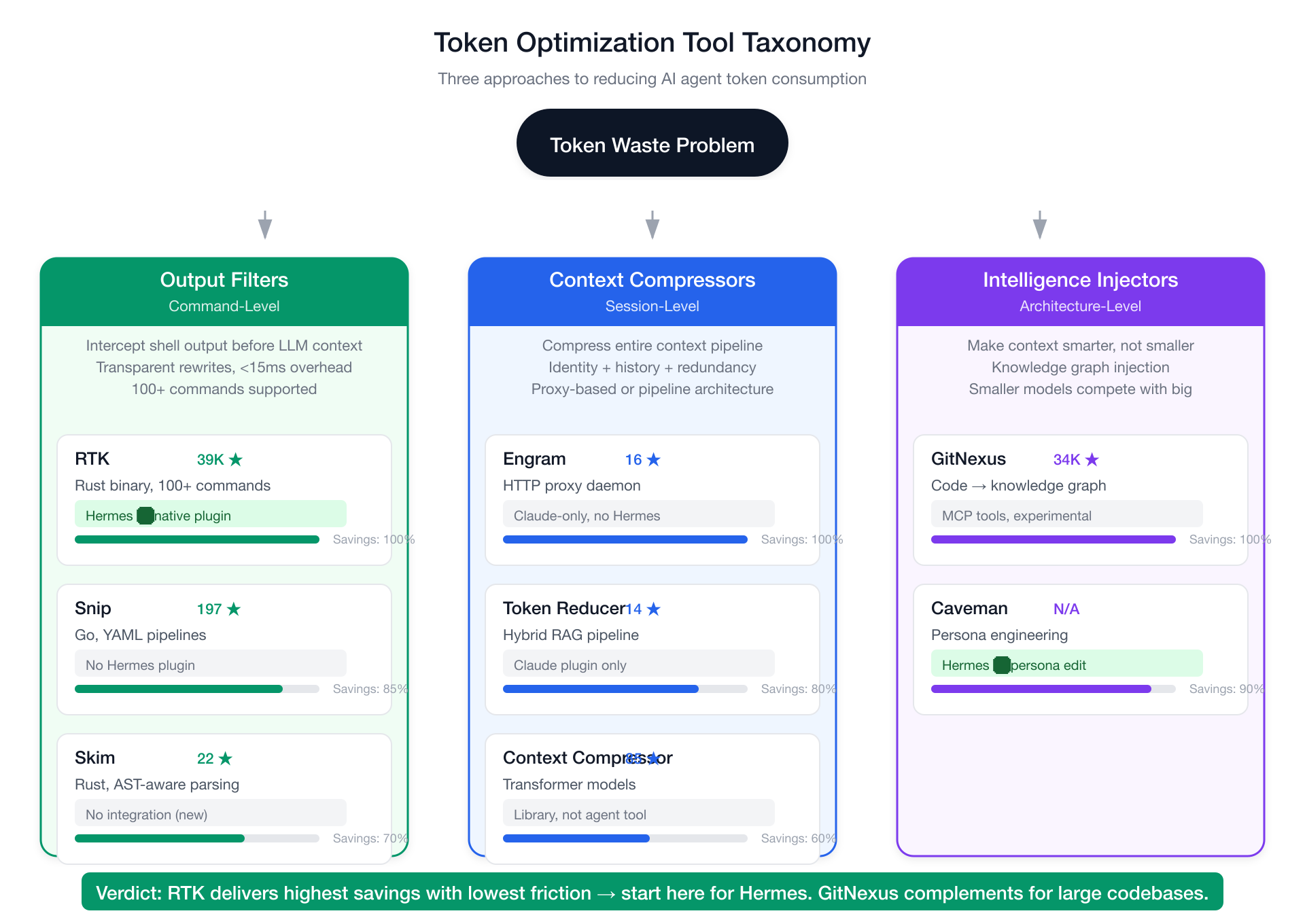
Token 优化工具可分为三个类别,背后是不同的哲学:
第一类:输出过滤器(命令级)
这些工具位于 Agent 和 Shell 之间,透明地重写或过滤命令输出,不让它进入 LLM 上下文窗口。优势:Agent 无感知、几乎零开销、立竿见影。局限:只压缩命令输出,对系统提示词、记忆、对话历史无能为力。
第二类:上下文压缩器(会话级)
这些工具压缩 Agent 的整个上下文 —— 系统提示词、对话历史、项目指令 —— 通过摘要、去重或语义索引。优势:对所有上下文类型都有节省。局限:摘要可能丢失细节,配置更复杂。
第三类:智能注入器(架构级)
这些工具不减少 token —— 它们让 token 更聪明。不发送原始文件内容,而是发送一个结构化、可查询的代码知识图谱。优势:Agent 用更少上下文完成更好的推理;让小模型也能媲美大模型。局限:需要索引,哲学完全不同。
逐款解析
RTK (Rust Token Killer) — 39,479 Stars
GitHub: rtk-ai/rtk 语言: Rust | 许可: MIT | 类别: 输出过滤器
RTK 是输出过滤领域的绝对王者。一个零依赖的 Rust 单二进制文件,支持 100+ 命令:git、测试运行器、包管理器、linter、AWS CLI、Docker、kubectl。每个命令延迟不到 10ms。
RTK 的杀手锏是自动重写钩子。运行一次 rtk init -g,Agent 执行的每个 shell 命令都会被透明重写为 rtk <command>。Agent 完全无感知 —— 它只收到压缩后的干净输出。
对于 Hermes,有官方插件:ogallotti/rtk-hermes(45 stars,MIT 许可)。这是一个 pre_tool_call 钩子,拦截 terminal() 调用并通过 rtk rewrite 重写命令。安装只需两行:
brew install rtk
pip install rtk-hermes
插件自动注册 —— 无需配置。所有重写逻辑都在 RTK 本体中,新过滤器自动生效。
实测节省(来自 rtk-hermes README):
cargo test:90-99%git log --stat:87%ls -la:78%git status:66%grep:52%
Snip — 197 Stars
GitHub: edouard-claude/snip 语言: Go | 许可: MIT | 类别: 输出过滤器
Snip 是 RTK 最有趣的竞争对手。它走了一条截然不同的路:过滤器是声明式 YAML 文件,不是编译代码。写一个 YAML 管道,放到文件夹里,完事。这让 Snip 的扩展性远胜 RTK —— 不需要懂 Rust 或 Go 就能添加新过滤器。
和 RTK 一样,Snip 通过钩子集成(snip init)。支持 Claude Code、Cursor、Copilot、Gemini CLI、Codex、Windsurf、Cline 等。内含基于 SQLite 的节省量追踪仪表板。
但是,Snip 没有 Hermes 专用插件。对 Hermes 用户来说,这意味着只能通过提示词注入(告诉 Agent 在命令前加 snip)来使用,而非透明重写 —— 体验差距明显。
Skim — 22 Stars
GitHub: dean0x/skim 语言: Rust | 许可: MIT | 类别: 输出过滤器(更聪明的那种)
Skim 是技术上最精致的输出过滤器。RTK 和 Snip 过滤的是命令输出文本,而 Skim 解析代码 AST,覆盖 17 种语言。它可以把一个 63,000 token 的 TypeScript 项目转换为:
- 结构模式:25,119 token(减少 60%)—— 把函数体显示为
{ /* ... */ } - 签名模式:7,328 token(减少 88%)—— 仅函数签名
- 类型模式:5,181 token(减少 92%)—— 仅类型定义
这和输出过滤有着本质区别。Skim 的 skim git diff 不仅能压缩 diff,还能识别哪些函数变了、显示其边界、并可选地将未变函数作为签名保留以提供架构上下文。
Skim 还有一个Token 预算级联功能:你设定一个 token 预算,Skim 自动选择能适配最激进的转换级别。有 10,000 token 空间就用结构模式,只有 3,000 token 就用签名模式。
代价:Skim 只有 22 stars,是新手。没有 Hermes 集成。
GitNexus — 34,066 Stars
GitHub: abhigyanpatwari/GitNexus 语言: TypeScript | 许可: PolyForm Noncommercial | 类别: 智能注入器
GitNexus 独树一帜。它不过滤输出 —— 它将代码库索引为知识图谱。运行 npx gitnexus analyze,GitNexus 解析每个文件、映射每个依赖、追踪每个调用链、识别架构簇。然后通过 MCP 工具将这些图谱暴露给 AI Agent。
核心理念:Agent 浪费 token,是因为缺乏上下文。它们盲目 grep、逐个读文件、遗漏跨文件依赖。GitNexus 用定向查询替代 —— "显示 processUser 的调用链"返回的正是相关子图,而不是 20 个文件的原始代码。
生态令人印象深刻:Claude Code 获得完整集成(MCP + 技能 + PreToolUse/PostToolUse 钩子)。Cursor、Codex、Windsurf、OpenCode 都有 MCP 支持。社区集成包括 pi-gitnexus、gitnexus-stable-ops 等,甚至有针对 Hermes 的实验性集成。
注意事项:PolyForm Noncommercial 许可意味着商业使用需要付费授权。Web UI 限制 ~5,000 个文件。Token 节省是间接的 —— 你省的是"更聪明地加载上下文"而非"压缩现有上下文"。
Engram — 16 Stars
GitHub: pythondatascrape/engram 语言: Go | 类别: 上下文压缩器
Engram 方案独特:它作为一个本地 HTTP 代理运行,拦截 LLM API 调用并压缩身份上下文(CLAUDE.md、系统提示词)和对话上下文(消息历史、工具结果)。
三个压缩阶段:
- 身份压缩:将冗长的 CLAUDE.md 推导为紧凑"密码本"—— 减少 96-98%
- 上下文压缩:旧对话历史折叠为
[CONTEXT_SUMMARY]块 —— 减少 40-60% - 冗余控制:检查大量工具输出中的重复内容以避免重新发送
总体节省:每会话 85-93%。但:只支持 Claude Code(OpenClaw 支持计划中),没有 Hermes 集成。
Token Reducer — 14 Stars
GitHub: Madhan230205/token-reducer 语言: Python | 许可: MIT | 类别: 上下文压缩器
Token Reducer 是一个本地优先的流水线,先索引代码库,再针对每个查询只检索最相关的上下文。采用混合方法:BM25 关键词匹配 + ONNX 向量语义搜索 + tree-sitter AST 分块 + TextRank 显著性评分 + 导入图依赖感知。
结果:节省 90-98% 的 token,同时保持语义相关性。设计为 Claude Code 插件,支持 /plugin 市场安装。
代价:比其它工具更重(Python 依赖,ML 模型用于嵌入),设计目标是代码库级上下文检索而非命令级输出过滤。没有 Hermes 集成。
Context Compressor — 85 Stars
GitHub: Huzaifa785/context-compressor 语言: Python | 许可: MIT | 类别: 文本压缩器
本列表中最偏学术的工具。Context Compressor 是一个 Python 库,使用 Transformer 模型(BERT、BART、T5)进行 AI 驱动的文本压缩。提供四种策略 —— 抽取式、抽象式、语义式、混合式 —— 并配合 ROUGE 质量指标。
设计用于 RAG 管道和 API 调用而非交互式 Agent 工作流。有 LangChain 集成和 FastAPI 微服务模式。由于模型推理延迟,对实时 Agent 工作流适用度较低。
额外:Caveman 模板(非独立仓库)
不是工具,是技法。Caveman 方法修改 Agent 人格使其输出极简、结构化。不用冗长解释,Agent 使用模板,token 消耗极低。与 RTK 结合使用可推动节省至 90-99%,如 adityahimaone/hermes-agent-rtk-caveman(25 stars)所示。
对 Hermes 而言,这意味着编辑人格文件强制简洁 —— 零成本,高效。
多维度对比总表
| 工具 | Stars | 类别 | Token 减少 | Hermes 集成 | 开销 | 易用性 | 许可 |
|---|---|---|---|---|---|---|---|
| RTK | 39K | 输出过滤 | 60-90% | ✅ 原生插件 | <10ms | ⭐⭐⭐⭐⭐ | MIT |
| Snip | 197 | 输出过滤 | 60-90% | ⚠️ 仅提示词 | <10ms | ⭐⭐⭐⭐ | MIT |
| Skim | 22 | 输出 (AST) | 60-92% | ❌ 无 | 14ms | ⭐⭐⭐⭐ | MIT |
| GitNexus | 34K | 智能注入 | 间接* | ⚠️ 实验性 | 索引耗时 | ⭐⭐⭐ | 非商用 |
| Engram | 16 | 上下文压缩 | 85-93% | ❌ 无 | <50ms | ⭐⭐⭐ | 不明 |
| Token Reducer | 14 | 上下文压缩 | 90-98% | ❌ 无 | 索引 + 查询 | ⭐⭐ | MIT |
| Context Compressor | 85 | 文本压缩 | 50-80% | ❌ 无 | ML 推理 | ⭐⭐ | MIT |
| Caveman | N/A | 行为优化 | 70-95% | ✅ 人格编辑 | 0ms | ⭐⭐⭐⭐⭐ | N/A |
* GitNexus 节省是间接的 —— 通过加载更智能的上下文来减少 token 浪费,而非压缩现有上下文。
关键解读
RTK 在 Hermes 维度全胜:最高 stars(最强社区验证),唯一有原生 Hermes 插件的工具,MIT 许可,<10ms 延迟,一行命令安装。在 token 优化栈的第一层没有对手。
GitNexus 是最有趣的互补工具。它不和 RTK 竞争 —— 它解决另一个问题。RTK 让命令输出变小;GitNexus 让 Agent 压根不需要那么多命令输出。二者结合,同时解决"多少上下文"和"什么上下文"两面。
Snip 的 YAML 方案技术上很优雅,但没有 Hermes 插件,集成摩擦太大。如果你是纯 Claude Code 用户,Snip 值得考虑 —— 它的扩展模型确实比 RTK 更好(加过滤器不需要 Rust)。
Skim 技术路线最有前途(AST 感知过滤),但太新且无 Hermes 集成。值得关注,尤其在它获得更多采用时。
上下文压缩器(Engram、Token Reducer、Context Compressor)解决的是更窄的问题(API 层压缩),无法与 Hermes 插件系统集成。有意思的思路,但暂时不实用。
Hermes 最优 Token 优化栈

综合分析 8 款工具后,推荐 Hermes Agent 用户的四层方案:
第一层:RTK Hermes 插件(透明输出过滤)
brew install rtk
pip install rtk-hermes
# 重启 Hermes —— 完成。
零持续投入即可获得 60-90% 命令 token 节省。插件是 rtk rewrite 的薄封装 —— 永远不会阻塞命令执行,RTK 不可用时会优雅降级,RTK 新增过滤器自动生效。
预估节省:命令输出 token 减少 60-90%。 配置时间:2 分钟。 持续维护:无。
第二层:人格优化(行为级压缩)
编辑 Hermes 人格文件,强化简洁行为。关键规则:
- 优先使用返回紧凑输出的工具 ——
rtk read替代cat,rtk grep替代rg等 - 不重复已知上下文 —— 用 memory 持久化事实,不反复解释
- 回复简洁 —— 回答问题,跳过铺垫
- 结构化输出(表格、列表)—— 每 token 信息密度更高
预估节省:Agent 回复 token 减少 30-50%。 配置时间:10 分钟。 持续维护:偶尔微调。
第三层:技能减负(上下文预算管理)
Hermes 每轮对话都加载所有技能描述。200+ 技能轻松吃掉几千 token。三个做法:
- 删掉不用技能:审查技能列表,删除从未用过的
- 技能保持精简:好的 SKILL.md 在 2,000 token 以内
- 触发条件聚焦:过于宽泛的触发条件导致不必要加载
预估节省:系统提示词减少 10,000-30,000 token/会话。 配置时间:一次性审计(30 分钟)。 持续维护:每月检查。
第四层(可选):GitNexus 用于重架构项目
如果你的代码库较大(50+ 文件、复杂依赖),GitNexus 提供的架构智能让每个 token 含金量更高:
npx gitnexus analyze # 索引代码库
# 然后为 Hermes 配置 MCP
预估节省:间接 —— 减少 40-60% 的无效搜索/读取操作。 配置时间:10 分钟(每项目一次索引)。 持续维护:重大重构后重新索引。
完整方案实战模拟
模拟一个 30 分钟 Hermes 会话的中型 Rust 项目:
| 上下文组成 | 无优化 | 第一层 (RTK) | +第二层 (人格) | +第三层 (技能) | +第四层 (GitNexus) |
|---|---|---|---|---|---|
| 系统提示词 + 技能 | 45,000 | 45,000 | 45,000 | 15,000 | 15,000 |
| 人格 / memory | 2,200 | 2,200 | 1,500 | 1,500 | 1,500 |
| 命令输出 | 118,000 | 23,600 | 23,600 | 23,600 | 15,000 |
| Agent 回复 | 50,000 | 50,000 | 25,000 | 25,000 | 25,000 |
| 无效搜索/读取 | 30,000 | 30,000 | 30,000 | 30,000 | 5,000 |
| 合计 token | 245,200 | 150,800 | 125,100 | 95,100 | 61,500 |
| 累计节省 | — | -38% | -49% | -61% | -75% |
总体减少 75% —— 从约 245,000 token 降至 61,500。按当前 API 价格,这就是 $2.45 vs $0.62 的区别。
关于"90-99% 节省"的宣传可信吗?
有些工具声称 90-99% token 节省。这些数字是真的,但指的是特定命令类型在隔离状态下,而非整个会话。rtk cargo test 确实能把 25,000 token 的测试运行压缩到 2,500 token(该命令节省 90%),但你无法对系统提示词、对话历史、Agent 回复也实现 90%。
用工具实现的全会话节省的现实天花板大约是 60-75%。达到 90%+ 需要行为改进(人格调优、严格控制 Agent 加载什么上下文)以及可能不同的架构(更短会话、更聚焦任务)。
结论:今天该装哪一个
如果你读完本文只做一件事:安装 RTK Hermes 插件。它是性价比最高、成本最低的优化:
brew install rtk && pip install rtk-hermes
两分钟,零维护,60-90% 命令输出节省。其余 —— 人格调优、技能减负、GitNexus —— 都是锦上添花。
Token 优化领域还很年轻,变化飞快。RTK 今天主宰战场,但 Skim 的 AST 感知方式和 GitNexus 的智能注入范式指明了前进方向:不是过滤上下文,而是让上下文更聪明。
来源
- RTK (Rust Token Killer) — CLI 代理,39K stars,MIT
- rtk-hermes 插件 — 官方 Hermes 集成
- hermes-agent-rtk-caveman — 90-99% 节省方案
- GitNexus — 客户端代码知识图谱
- Snip — YAML 驱动的 token 优化器
- Skim — AST 感知上下文优化引擎
- Engram — 本地上下文压缩守护进程
- Token Reducer — 混合 RAG 上下文压缩流水线
- Context Compressor — Transformer 文本压缩库